Delivering Data Happiness
/Recently, a happiness meme has been making its way around the data quality blogosphere.
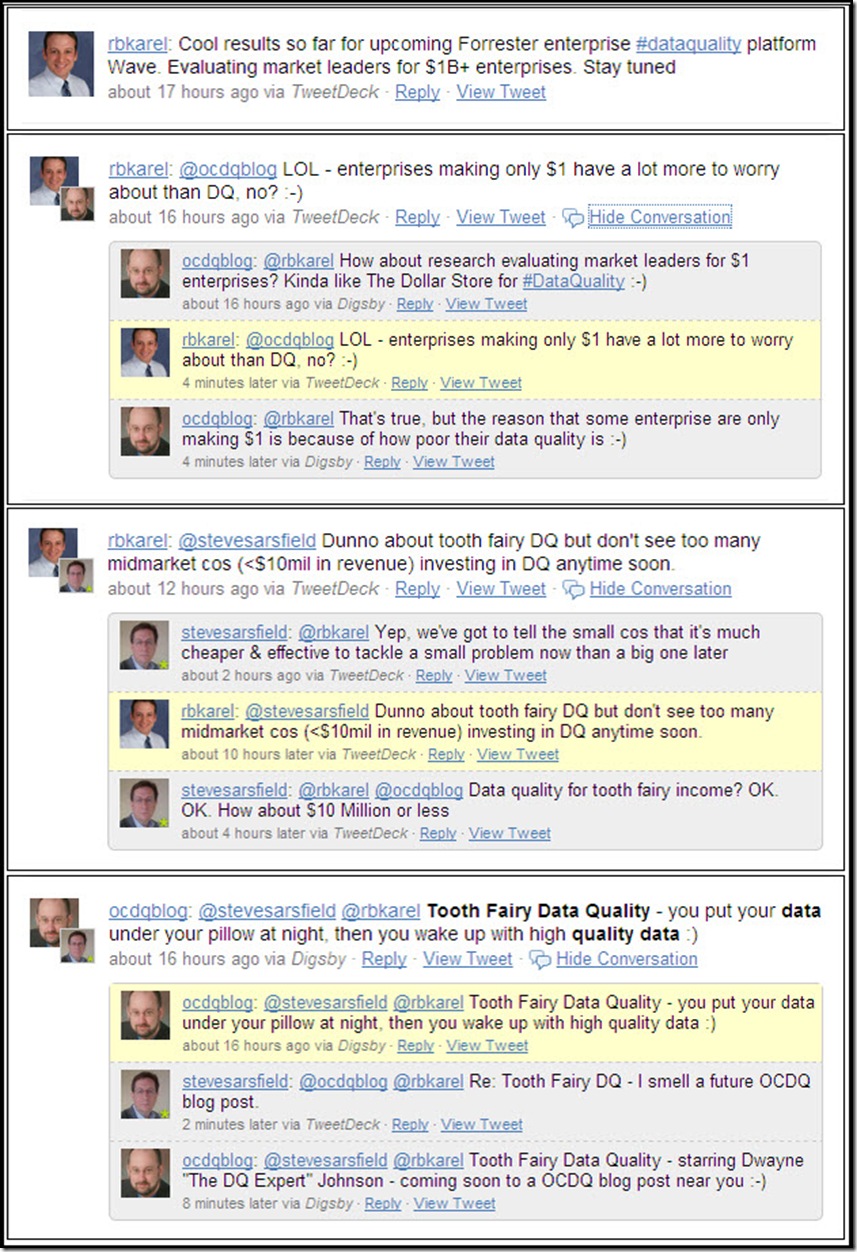
Its origins have been traced to a lovely day in Denmark when Henrik Liliendahl Sørensen, with help from The Muppet Show, asked “Why do you watch it?” referring to the typically negative spin in the data quality blogosphere, where it seems we are:
“Always describing how bad data is everywhere.
Bashing executives who don’t get it.
Telling about all the hard obstacles ahead. Explaining you don’t have to boil the ocean but might get success by settling for warming up a nice little drop of water.
Despite really wanting to tell a lot of success stories, being the funny Fozzie Bear on the stage, well, I am afraid I also have been spending most of my time on the balcony with Statler and Waldorf.
So, from this day forward: More success stories.”
In his recent blog posts, The Ugly Duckling and Data Quality Tools: The Cygnets in Information Quality, Henrik has been sharing more success stories, or to phrase it in an even happier way: delivering data happiness.
Delivering Data Happiness
I am reading the great book Delivering Happiness: A Path to Profits, Passion, and Purpose by Tony Hsieh, the CEO of Zappos.
Obviously, the book’s title inspired the title of this blog post.
One of the Zappos core values is “build a positive team and family spirit,” and I have been thinking about how that applies to data quality improvements, which are often pursued as one of the many aspects of a data governance program.
Most data governance maturity models describe an organization’s evolution through a series of stages intended to measure its capability and maturity, tendency toward being reactive or proactive, and inclination to be project-oriented or program-oriented.
Most data governance programs are started by organizations that are confronted with a painfully obvious need for improvement.
The primary reason that the change management efforts of data governance are resisted is because they rely almost exclusively on negative methods—they emphasize broken business and technical processes, as well as bad data-related employee behaviors.
Although these problems exist and are the root cause of some of the organization’s failures, there are also unheralded processes and employees that prevented other problems from happening, which are the root cause of some of the organization’s successes.
“The best team members,” writes Hsieh while explaining the Zappos core values, “take initiative when they notice issues so that the team and the company can succeed.”
“The best team members take ownership of issues and collaborate with other team members whenever challenges arise.”
“The best team members have a positive influence on one another and everyone they encounter. They strive to eliminate any kind of cynicism and negative interactions.”
The change management efforts of data governance and other enterprise information initiatives often make it sound like no such employees (i.e., “best team members”) currently exist anywhere within an organization.
The blogosphere, as well as critically acclaimed books and expert presentations at major industry conferences, often seem to be in unanimous and unambiguous agreement in the message that they are broadcasting:
“Everything your organization is currently doing regarding data management is totally wrong!”
Sadly, that isn’t much of an exaggeration. But I am not trying to accuse anyone of using Machiavellian sales tactics to sell solutions to non-existent problems—poor data quality and data governance maturity are costly realities for many organizations.
Nor am I trying to oversimplify the many real complexities involved when implementing enterprise information initiatives.
However, most of these initiatives focus exclusively on developing new solutions and best practices, failing to even acknowledge the possible presence of existing solutions and best practices.
The success of all enterprise information initiatives requires the kind of enterprise-wide collaboration that is facilitated by the “best team members.” But where, exactly, do the best team members come from? Should it really be surprising whenever an enterprise information initiative can’t find any using exclusively negative methods, focusing only on what is currently wrong?
As Gordon Hamilton commented on my previous post, we need to be “helping people rise to the level of the positive expectations, rather than our being codependent in their sinking to the level of the negative expectations.”
We really need to start using more positive methods for fostering change.
Let’s begin by first acknowledging the best team members who are currently delivering data happiness to our organizations.
Related Posts
Why isn’t our data quality worse?
Declaration of Data Governance
The Balancing Act of Awareness
Podcast: Business Technology and Human-Speak


 Understanding your
Understanding your 
 I grew up and lived most of my life in the suburbs of Boston, Massachusetts. But just prior to relocating to the Midwest for work seven years ago, I lived in Derry, New Hampshire, just down the road from the
I grew up and lived most of my life in the suburbs of Boston, Massachusetts. But just prior to relocating to the Midwest for work seven years ago, I lived in Derry, New Hampshire, just down the road from the