
To Parse or Not To Parse
/“To Parse, or Not To Parse,—that is the question:
Whether 'tis nobler in the data to suffer
The slings and arrows of free-form fields,
Or to take arms against a sea of information,
And by parsing, understand them?”
Little known fact: before William Shakespeare made it big as a playwright, he was a successful data quality consultant.
Alas, poor data quality! The Bard of Avon knew it quite well. And he was neither a fan of free verse nor free-form fields.
Free-Form Fields
A free-form field contains multiple (usually interrelated) sub-fields. Perhaps the most common examples of free-form fields are customer name and postal address.
A Customer Name field with the value “Christopher Marlowe” is comprised of the following sub-fields and values:
- Given Name = “Christopher”
- Family Name = “Marlowe”
A Postal Address field with the value “1587 Tambur Lane” is comprised of the following sub-fields and values:
- House Number = “1587”
- Street Name = “Tambur”
- Street Type = “Lane”
Obviously, both of these examples are simplistic. Customer name and postal address are comprised of additional sub-fields, not all of which will be present on every record or represented consistently within and across data sources.
Returning to the bard's question, a few of the data quality reasons to consider parsing free-form fields include:
- Data Profiling
- Data Standardization
- Data Matching
Much Ado About Analysis
Free-form fields are often easier to analyze as formats constructed by parsing and classifying the individual values within the field. In Adventures in Data Profiling (Part 5), a data profiling tool was used to analyze the field Postal Address Line 1:
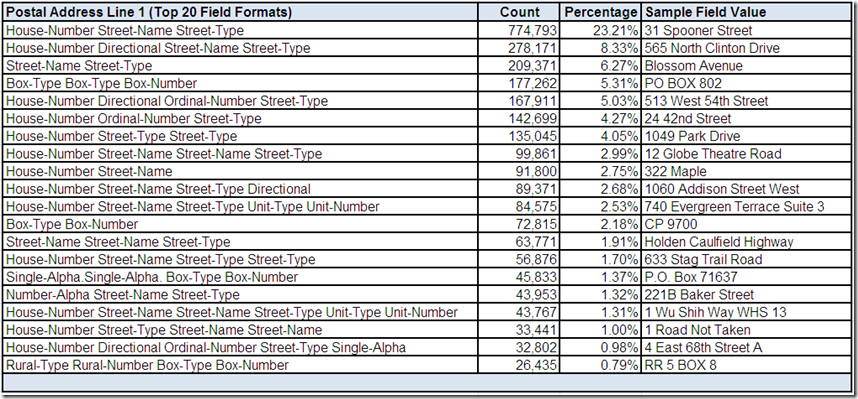
The Taming of the Variations
Free-form fields often contain numerous variations resulting from data entry errors, different conventions for representing the same value, and a general lack of data quality standards. Additional variations are introduced by multiple data sources, each with its own unique data characteristics and quality challenges.
Data standardization parses free-form fields to break them down into their smaller individual sub-fields to gain improved visibility of the available input data. Data standardization is the taming of the variations that creates a consistent representation, applies standard values where appropriate, and when possible, populates missing values.
The following example shows parsed and standardized postal addresses:
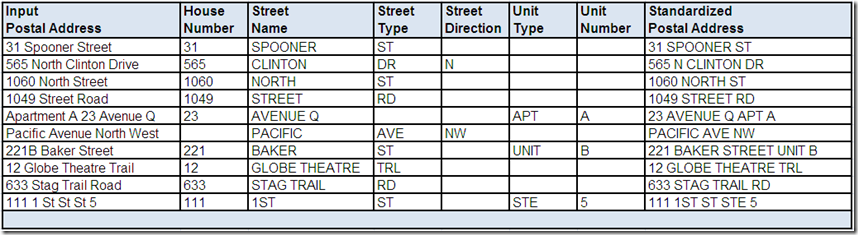
In your data quality implementations, do you use this functionality for processing purposes only? If you retain the standardized results, do you store the parsed and standardized sub-fields or just the standardized free-form value?
Shall I compare thee to other records?
Data matching often uses data standardization to prepare its input. This allows for more direct and reliable comparisons of parsed sub-fields with standardized values, decreases the failure to match records because of data variations, and increases the probability of effective match results.
Imagine matching the following product description records with and without the parsed and standardized sub-fields:
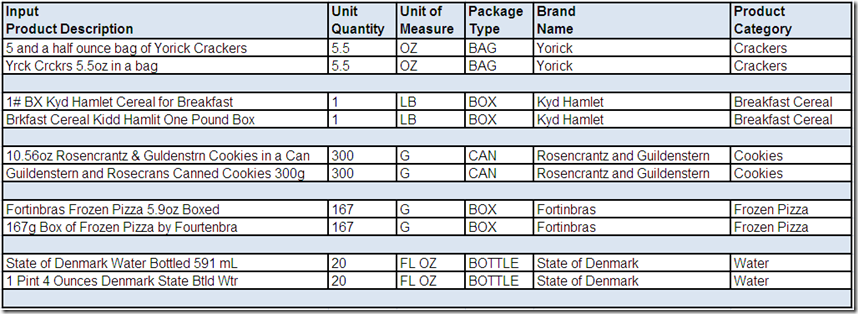
Doth the bard protest too much?
Please share your thoughts and experiences regarding free-form fields.

