Data Quality in Six Verbs
/Once upon a time when asked on Twitter to identify a list of critical topics for data quality practitioners, my pithy (with only 140 characters in a tweet, pithy is as good as it gets) response was, and especially since I prefer emphasizing the need to take action, to propose six critical verbs: Investigate, Communicate, Collaborate, Remediate, Inebriate, and Reiterate.
Lest my pith be misunderstood aplenty, this blog post provides more detail, plus links to related posts, about what I meant.
1 — Investigate
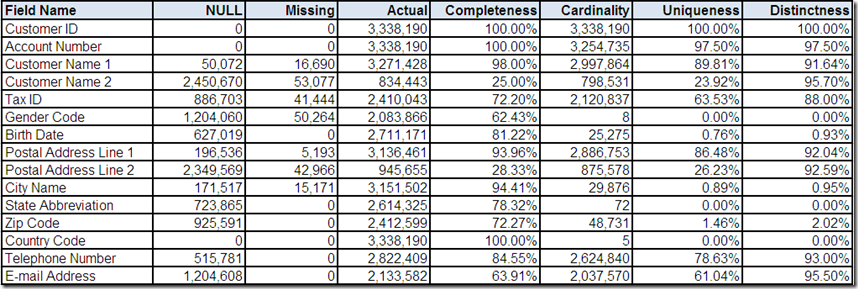
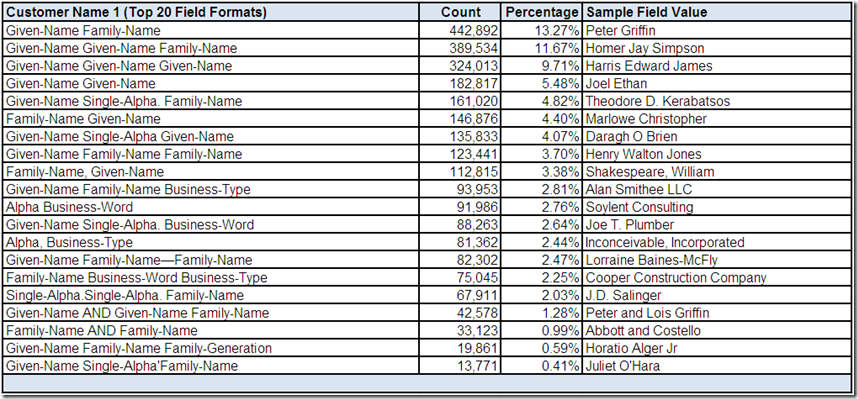
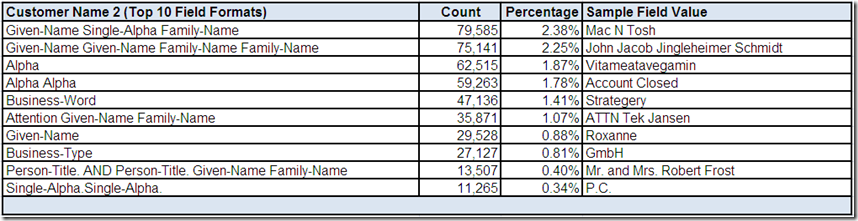
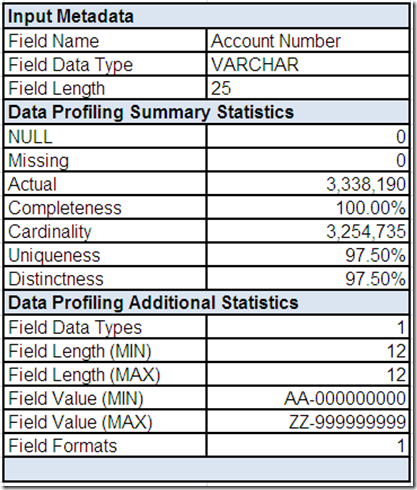
Data quality is not exactly a riddle wrapped in a mystery inside an enigma. However, understanding your data is essential to using it effectively and improving its quality. Therefore, the first thing you must do is investigate.
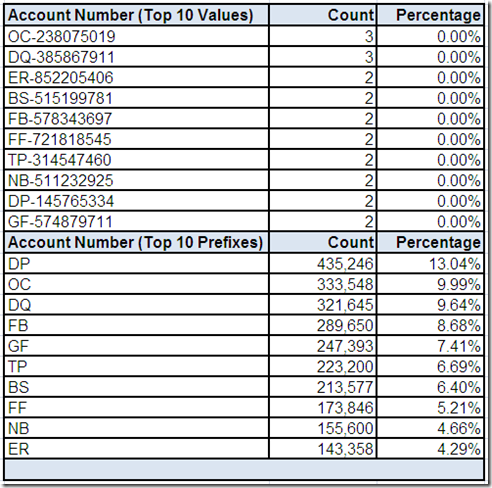
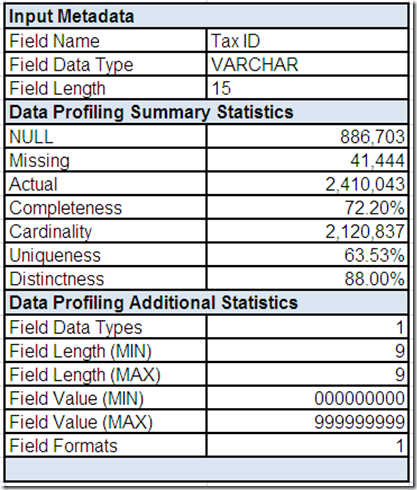
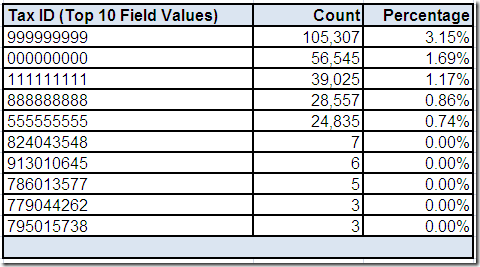
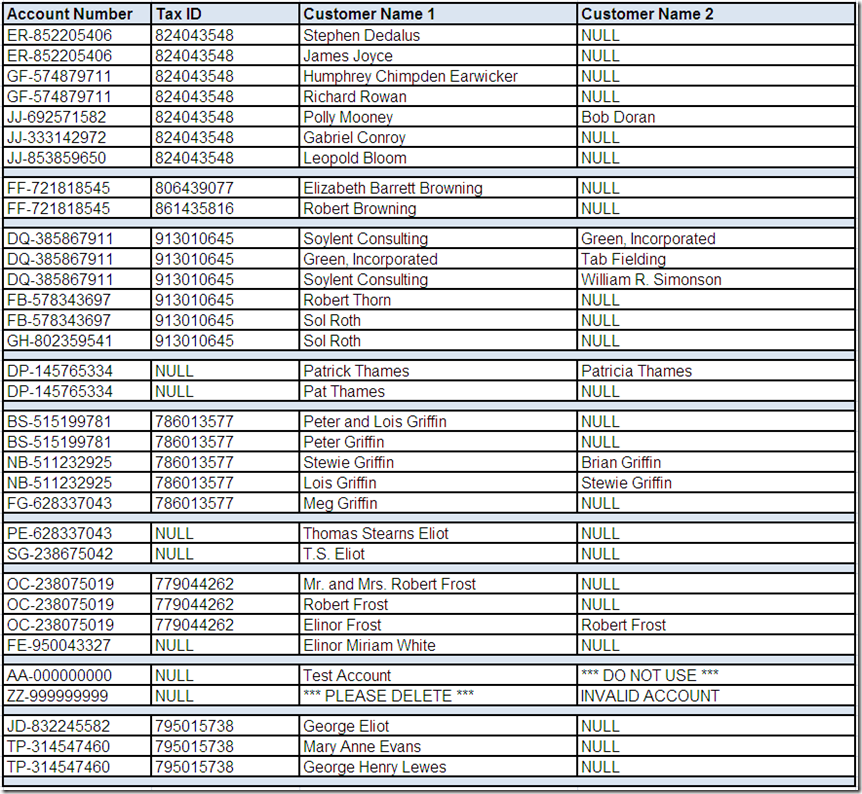
So, grab your favorite (preferably highly caffeinated) beverage, get settled into your comfy chair, roll up your sleeves and starting analyzing that data. Data profiling tools can be very helpful with raw data analysis.
However, data profiling is elementary, my dear reader. In order for you to make sense of those data elements, you require business context. This means you must also go talk with data’s best friends—its stewards, analysts, and subject matter experts.
Six blog posts related to Investigate:
- The First Law of Data Quality
- Follow the Data
- Getting Your Data Freq On
- Adventures in Data Profiling
- The Real Data Value is Business Insight
- The Stone Wars of Root Cause Analysis
2 — Communicate
After you have completed your preliminary investigation, the next thing you must do is communicate your findings, which helps improve everyone’s understanding of how data is being used, verify data’s business relevancy, and prioritize critical issues.
Keep in mind that communication is mostly about listening. Also, be prepared to face “data denial” whenever data quality is discussed. This is a natural self-defense mechanism for the people responsible for business processes, technology, and data, which is understandable because nobody likes to be blamed (or feel blamed) for causing or failing to fix data quality problems.
No matter how uncomfortable these discussions may be at times, they are essential to evaluating the potential ROI of data quality improvements, defining data quality standards, and most importantly, providing a working definition of success.
Six blog posts related to Communicate:
- Hailing Frequencies Open
- Stop Tapping and Start Talking
- “Some is not a number and soon is not a time”
- The Seventh Law of Data Quality
- Selling the Business Benefits of Data Quality
- The Baseball Strike Zone and Data Quality
3 — Collaborate
After you have investigated and communicated, now you must rally the team that will work together to improve the quality of your data. A cross-disciplinary team will be needed because data quality is neither a business nor a technical issue—it is both.
Therefore, you will need the collaborative effort of business and technical folks. The business folks usually own the data, or at least the business processes that create it, so they understand its meaning and daily use. The technical folks usually own the hardware and software comprising your data architecture. Both sets of folks must realize they are all “one company folk” that must collaborate in order to be successful.
No, you don’t need a folk singer, but you may need an executive sponsor. The need for collaboration might sound rather simple, but as one of my favorite folk singers taught me, sometimes the hardest thing to learn is the least complicated.
Six blog posts related to Collaborate:
- The Third Law of Data Quality
- Turning the M Upside Down
- The Algebra of Collaboration
- The Road of Collaboration
- The Psychology of Collaboration
- The Collaborative Culture of Data Governance
4 — Remediate
Resolving data quality issues requires a combination of data cleansing and defect prevention. Data cleansing is reactive and its common (and deserved) criticism is that it essentially treats the symptoms without curing the disease.
Defect prevention is proactive and through root cause analysis and process improvements, it essentially is the cure for the quality ills that ail your data. However, a data governance framework is often necessary for defect prevention to be successful. As is patience and understanding since it will require a strategic organizational transformation that doesn’t happen overnight.
The unavoidable reality is that data cleansing is used to correct today’s problems while defect prevention is busy building a better tomorrow for your organization. Fundamentally, data quality requires a hybrid discipline that combines data cleansing and defect prevention into an enterprise-wide best practice.
Six blog posts related to Remediate:
- Hyperactive Data Quality (Second Edition)
- What going to the dentist taught me about data quality
- How Data Cleansing Saves Lives
- The Fallacy of Defect Prevention
- Is your data complete and accurate, but useless to your business?
- Data Quality and Miracle Exceptions
5 — Inebriate
I am not necessarily advocating that kind of inebriation. Instead, think Emily Dickinson (i.e., “Inebriate of air am I” – it’s a line from a poem about happiness that, yes, also happens to make a good drinking song).
My point is that you must not only celebrate your successes, but celebrate them quite publicly. Channel yet another poet (Walt Whitman) and sound your barbaric yawp over the cubicles of your company: “We just improved the quality of our data!”
Of course, you will need to be more specific. Declare success using words illustrating the business impact of your achievements, such as mitigated risks, reduced costs, or increased revenues — those three are always guaranteed executive crowd pleasers.
Six blog posts related to Inebriate:
- Why isn’t our data quality worse?
- Delivering Data Happiness
- DQ-View: Achieving Data Quality Happiness
- Video: Declaration of Data Governance
- Data Love Song Mashup
- Video: Oh, the Data You’ll Show!
6 — Reiterate
Like the legend of the phoenix, the end is also a new beginning. Therefore, don’t get too inebriated, since you are not celebrating the end of your efforts. Your data quality journey has only just begun. Your continuous monitoring must continue and your ongoing improvements must remain ongoing. Which is why, despite the tension this reality, and this bad grammatical pun, might cause you, always remember that the tense of all six of these verbs is future continuous.
Six blog posts related to Reiterate:
- Data Quality is not an Act, it is a Habit
- The Second Law of Data Quality
- Data Quality: Quo Vadimus?
- The Role Of Data Quality Monitoring In Data Governance
- Monitoring Data Quality a Little Too Continuously
- The Stakeholder’s Dilemma
What Say You?
Please let me know what you think, pithy or otherwise, by posting a comment below. And feel free to use more than six verbs.








 Understanding your
Understanding your