Data Governance Frameworks are like Jigsaw Puzzles
/
In a recent interview, Jill Dyché explained a common misconception, namely that a data governance framework is not a strategy. “Unlike other strategic initiatives that involve IT,” Jill explained, “data governance needs to be designed. The cultural factors, the workflow factors, the organizational structure, the ownership, the political factors, all need to be accounted for when you are designing a data governance roadmap.”
“People need a mental model, that is why everybody loves frameworks,” Jill continued. “But they are not enough and I think the mistake that people make is that once they see a framework, rather than understanding its relevance to their organization, they will just adapt it and plaster it up on the whiteboard and show executives without any kind of context. So they are already defeating the purpose of data governance, which is to make it work within the context of your business problems, not just have some kind of mental model that everybody can agree on, but is not really the basis for execution.”
“So it’s a really, really dangerous trend,” Jill cautioned, “that we see where people equate strategy with framework because strategy is really a series of collected actions that result in some execution — and that is exactly what data governance is.”
And in her excellent article Data Governance Next Practices: The 5 + 2 Model, Jill explained that data governance requires a deliberate design so that the entire organization can buy into a realistic execution plan, not just a sound bite. As usual, I agree with Jill, since, in my experience, many people expect a data governance framework to provide eureka-like moments of insight.
In The Myths of Innovation, Scott Berkun debunked the myth of the eureka moment using the metaphor of a jigsaw puzzle.
“When you put the last piece into place, is there anything special about that last piece or what you were wearing when you put it in?” Berkun asked. “The only reason that last piece is significant is because of the other pieces you’d already put into place. If you jumbled up the pieces a second time, any one of them could turn out to be the last, magical piece.”
“The magic feeling at the moment of insight, when the last piece falls into place,” Berkun explained, “is the reward for many hours (or years) of investment coming together. In comparison to the simple action of fitting the puzzle piece into place, we feel the larger collective payoff of hundreds of pieces’ worth of work.”
Perhaps the myth of the data governance framework could also be debunked using the metaphor of a jigsaw puzzle.
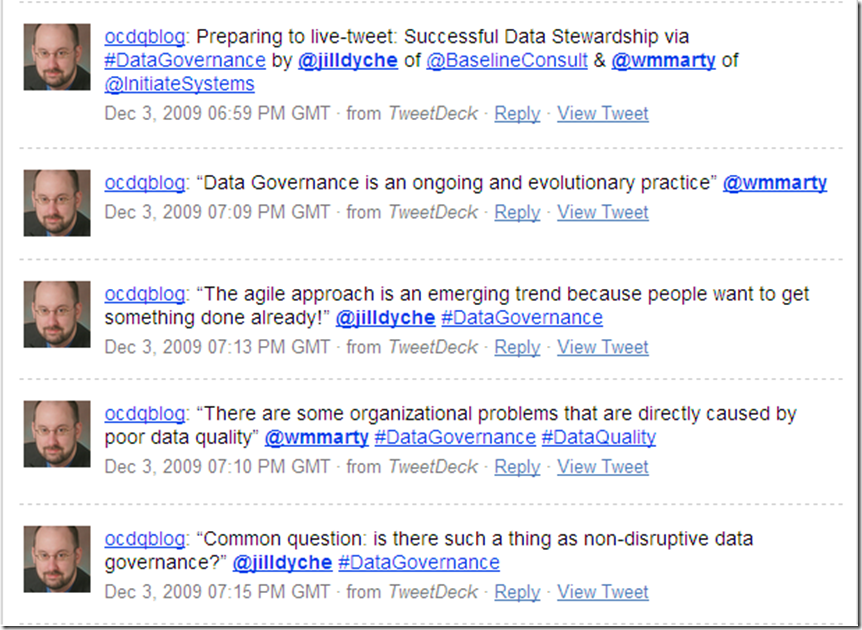
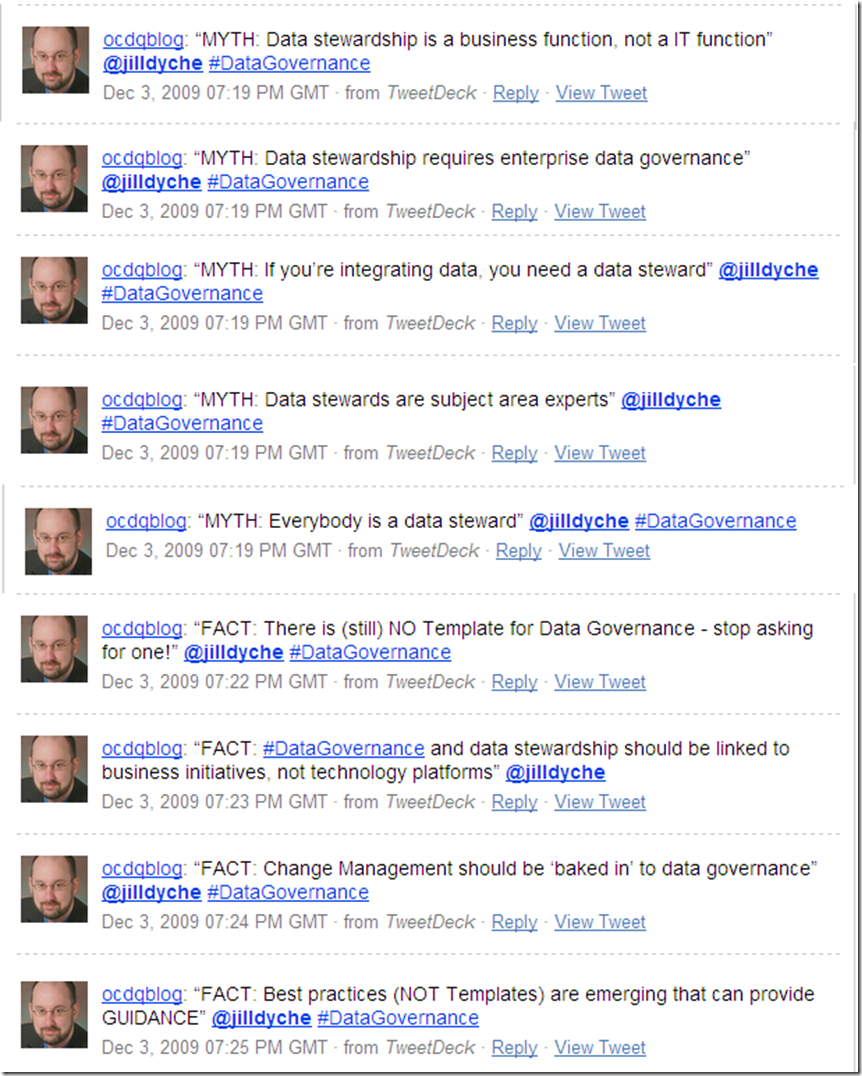
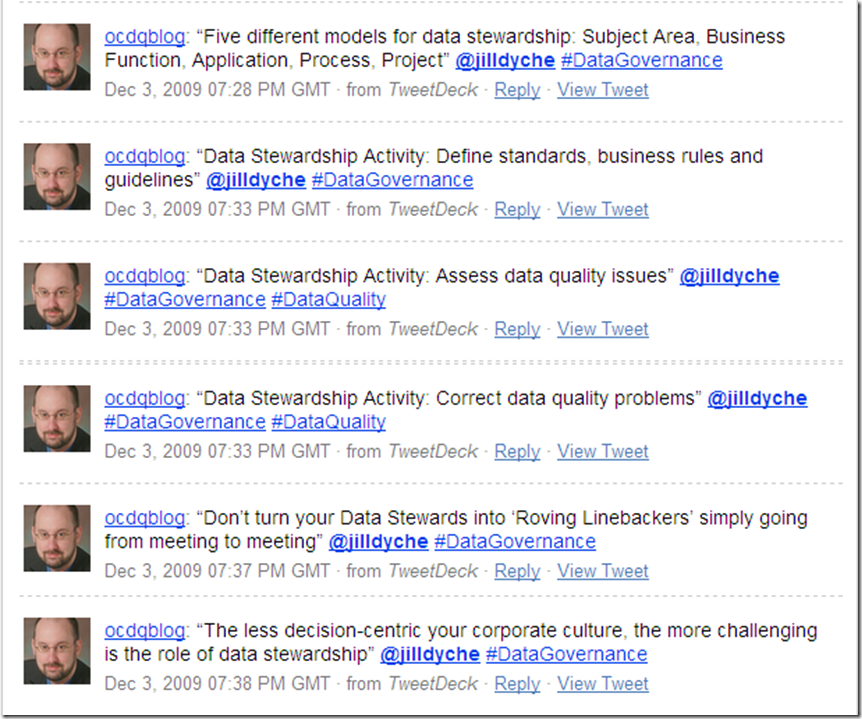
Data governance requires the coordination of a complex combination of a myriad of factors, including executive sponsorship, funding, decision rights, arbitration of conflicting priorities, policy definition, policy implementation, data quality remediation, data stewardship, business process optimization, technology enablement, change management — and many other puzzle pieces.
How could a data governance framework possibly predict how you will assemble the puzzle pieces? Or how the puzzle pieces will fit together within your unique corporate culture? Or which of the many aspects of data governance will turn out to be the last (or even the first) piece of the puzzle to fall into place in your organization? And, of course, there is truly no last piece of the puzzle, since data governance is an ongoing program because the business world constantly gets jumbled up by change.
So, data governance frameworks are useful, but only if you realize that data governance frameworks are like jigsaw puzzles.