The Big Blue Bird: IBM partners with Twitter
/This sponsored blog post for the IBM for Midsize Business program examines the new partnership between IBM and Twitter.
Read MoreThis sponsored blog post for the IBM for Midsize Business program examines the new partnership between IBM and Twitter.
Read MoreAn example of the importance of good data quality provided by a bad DVR television guide description of Sesame Street.
Read MoreOn March 13, 2009 I launched this blog and, just a month away from its 5th anniversary, this was its 500th post. For following Obsessive-Compulsive Data Quality for 5 years and 500 posts, I offer 5 words: Thank you all very much.
Read MoreIn this eight-minute video, I attempt to demystify social media, which is often over-identified with the technology that enables it, when, in fact, we have always been social, and we have always used media, because social media is about human communication, about humans communicating in the same ways they have always communicated, by sharing images, memories, stories, words, and more often nowadays, we are communicating by sharing photographs, videos, and messages via social media status updates.
This video briefly discusses the three social media services used by my local Toastmasters club — Pinterest, Vimeo, and Twitter — and concludes with an analogy inspired by The Emerald City and The Yellow Brick Road from The Wizard of Oz:
If you are having trouble viewing this video, then you can watch it on Vimeo by clicking on this link: Demystifying Social Media
You can also watch a regularly updated page of my videos by clicking on this link: OCDQ Videos
Brevity is the Soul of Social Media
The Wisdom of the Social Media Crowd
The Challenging Gift of Social Media
Can Social Media become a Universal Translator?
Recently on Twitter, Daragh O Brien and I discussed his proposed concept. “After Big Data,” Daragh tweeted, “we will inevitably begin to see the rise of MOData as organizations seek to grab larger chunks of data and digest it. What is MOData? It’s MO’Data, as in MOre Data. Or Morbidly Obese Data. Only good data quality and data governance will determine which.”
Daragh asked if MO’Data will be the Big Data Killer. I said only if MO’Data doesn’t include MO’BusinessInsight, MO’DataQuality, and MO’DataPrivacy (i.e., more business insight, more data quality, and more data privacy).
“But MO’Data is about more than just More Data,” Daragh replied. “It’s about avoiding Morbidly Obese Data that clogs data insight and data quality, etc.”
I responded that More Data becomes Morbidly Obese Data only if we don’t exercise better data management practices.
Agreeing with that point, Daragh replied, “Bring on MOData and the Pilates of Data Quality and Data Governance.”
To slightly paraphrase lines from one of my favorite movies — Airplane! — the Cloud is getting thicker and the Data is getting laaaaarrrrrger. Surely I know well that growing data volumes is a serious issue — but don’t call me Shirley.
Whether you choose to measure it in terabytes, petabytes, exabytes, HoardaBytes, or how much reality bites, the truth is we were consuming way more than our recommended daily allowance of data long before the data management industry took a tip from McDonald’s and put the word “big” in front of its signature sandwich. (Oh great . . . now I’m actually hungry for a Big Mac.)
But nowadays with silos replicating data, as well as new data, and new types of data, being created and stored on a daily basis, our data is resembling the size of Bob Parr in retirement, making it seem like not even Mr. Incredible in his prime possessed the super strength needed to manage all of our data. Those were references to the movie The Incredibles, where Mr. Incredible was a superhero who, after retiring into civilian life under the alias of Bob Parr, elicits the observation from this superhero costume tailor: “My God, you’ve gotten fat.” Yes, I admit not even Helen Parr (aka Elastigirl) could stretch that far for a big data joke.
Although Daragh’s concerns about morbidly obese data are valid, no superpowers (or other miracle exceptions) are needed to manage all of our data. In fact, it’s precisely when we are so busy trying to manage all of our data that we hoard countless bytes of data without evaluating data usage, gathering data requirements, or planning for data archival. It’s like we are trying to lose weight by eating more and exercising less, i.e., consuming more data and exercising less data quality and data governance. As Daragh said, only good data quality and data governance will determine whether we get more data or morbidly obese data.
Losing weight requires a healthy approach to both diet and exercise. A healthy approach to diet includes carefully choosing the food you consume and carefully controlling your portion size. A healthy approach to exercise includes a commitment to exercise on a regular basis at a sufficient intensity level without going overboard by spending several hours a day, every day, at the gym.
Swimming is a great form of exercise, but swimming in big data without having a clear business objective before you jump into the pool is like telling your boss that you didn’t get any work done because you decided to spend all day working out at the gym.
Carefully choosing the data you consume and carefully controlling your data portion size is becoming increasingly important since big data is forcing us to revisit information overload. However, the main reason that traditional data management practices often become overwhelmed by big data is because traditional data management practices are not always the right approach.
We need to acknowledge that some big data use cases differ considerably from traditional ones. Data modeling is still important and data quality still matters, but how much data modeling and data quality is needed before big data can be effectively used for business purposes will vary. In order to move the big data discussion forward, we have to stop fiercely defending our traditional perspectives about structure and quality. We also have to stop fiercely defending our traditional perspectives about analytics, since there will be some big data use cases where depth and detailed analysis may not be necessary to provide business insight.
Jim Ericson explained that your data is big enough. Rich Murnane explained that bigger isn’t better, better is better. Although big data may indeed be followed by more data that doesn’t necessarily mean we require more data management in order to prevent more data from becoming morbidly obese data. I think that we just need to exercise better data management.
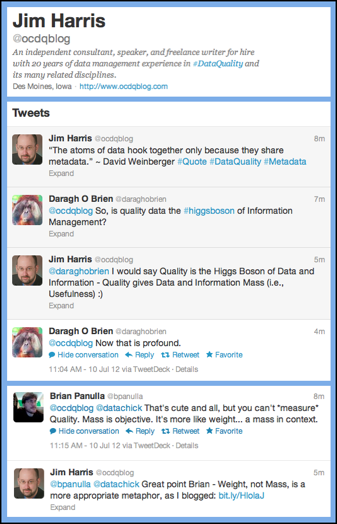 Recently on Twitter, Daragh O Brien replied to my David Weinberger quote “The atoms of data hook together only because they share metadata,” by asking “So, is Quality Data the Higgs Boson of Information Management?”
Recently on Twitter, Daragh O Brien replied to my David Weinberger quote “The atoms of data hook together only because they share metadata,” by asking “So, is Quality Data the Higgs Boson of Information Management?”
I responded that Quality is the Higgs Boson of Data and Information since Quality gives Data and Information their Mass (i.e., their Usefulness).
“Now that is profound,” Daragh replied.
“That’s cute and all,” Brian Panulla interjected, “but you can’t measure Quality. Mass is objective. It’s more like Weight — a mass in context.”
I agreed with Brian’s great point since in a previous post I explained the often misunderstood difference between mass, an intrinsic property of matter based on atomic composition, and weight, a gravitational force acting on matter.
Using these concepts metaphorically, mass is an intrinsic property of data, representing objective data quality, whereas weight is a gravitational force acting on data, thereby representing subjective data quality.
But my previous post didn’t explain where matter theoretically gets its mass, and since this scientific mystery was radiating in the cosmic background of my Twitter banter with Daragh and Brian, I decided to use this post to attempt a brief explanation along the way to yet another data quality analogy.
As you have probably heard by now, big scientific news was recently reported about the discovery of the Higgs Boson, which, since the 1960s, the Standard Model of particle physics has theorized to be the fundamental particle associated with a ubiquitous quantum field (referred to as the Higgs Field) that gives all matter its mass by interacting with the particles that make up atoms and weighing them down. This is foundational to our understanding of the universe because without something to give mass to the basic building blocks of matter, everything would behave the same way as the intrinsically mass-less photons of light behave, floating freely and not combining with other particles. Therefore, without mass, ordinary matter, as we know it, would not exist.
I like the Higgs Field explanation provided by Brian Cox and Jeff Forshaw. “Imagine you are blindfolded, holding a ping-pong ball by a thread. Jerk the string and you will conclude that something with not much mass is on the end of it. Now suppose that instead of bobbing freely, the ping-pong ball is immersed in thick maple syrup. This time if you jerk the thread you will encounter more resistance, and you might reasonably presume that the thing on the end of the thread is much heavier than a ping-pong ball. It is as if the ball is heavier because it gets dragged back by the syrup.”
“Now imagine a sort of cosmic maple syrup that pervades the whole of space. Every nook and cranny is filled with it, and it is so pervasive that we do not even know it is there. In a sense, it provides the backdrop to everything that happens.”
Mass is therefore generated as a result of an interaction between the ping-pong balls (i.e., atomic particles) and the maple syrup (i.e, the Higgs Field). However, although the Higgs Field is pervasive, it is also variable and selective, since some particles are affected by the Higgs Field more than others, and photons pass through it unimpeded, thereby remaining mass-less particles.
Now that I have vastly oversimplified the Higgs Field, let me Get Higgy with It by attempting an analogy for data quality based on the Higgs Field. As I do, please remember the wise words of Karen Lopez: “All analogies are perfectly imperfect.”
Quality provides the backdrop to everything that happens when we use data. Data in the wild, independent from use, is as carefree as the mass-less photon whizzing around at the speed of light, like a ping-pong ball bouncing along without a trace of maple syrup on it. But once we interact with data using our sticky-maple-syrup-covered fingers, data begins to slow down, begins to feel the effects of our use. We give data mass so that it can become the basic building blocks of what matters to us.
Some data is affected more by our use than others. The more subjective our use, the more we weigh data down. The more objective our use, the less we weigh data down. Sometimes, we drag data down deep into the maple syrup, covering data up with an application layer, or bottling data into silos. Other times, we keep data in the shallow end of the molasses swimming pool.
Quality is the Higgs Field of Data. As users of data, we are the Higgs Bosons — we are the fundamental particles associated with a ubiquitous data quality field. By using data, we give data its quality. The quality of data can not be separated from its use any more than the particles of the universe can be separated from the Higgs Field.
The closest data equivalent of a photon, a ping-pong ball particle that doesn’t get stuck in the maple syrup of the Higgs Field, is Open Data, which doesn’t get stuck within silos, but is instead data freely shared without the sticky quality residue of our use.
Our Increasingly Data-Constructed World
What is Weighing Down your Data?
Data Myopia and Business Relativity
Are Applications the La Brea Tar Pits for Data?
Sometimes it’s Okay to be Shallow
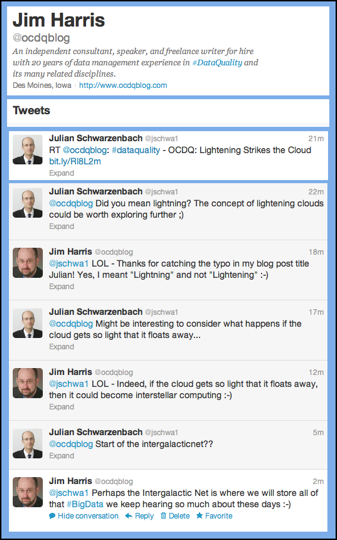 Last week, when I published my blog post Lightning Strikes the Cloud, I unintentionally demonstrated three important things about data quality.
Last week, when I published my blog post Lightning Strikes the Cloud, I unintentionally demonstrated three important things about data quality.
The first thing I demonstrated was even an obsessive-compulsive data quality geek is capable of data defects, since I initially published the post with the title Lightening Strikes the Cloud, which is an excellent example of the difference between validity and accuracy caused by the Cupertino Effect, since although lightening is valid (i.e., a correctly spelled word), it isn’t contextually accurate.
The second thing I demonstrated was the value of shining a social light on data quality — the value of using collaborative tools like social media to crowd-source data quality improvements. Thankfully, Julian Schwarzenbach quickly noticed my error on Twitter. “Did you mean lightning? The concept of lightening clouds could be worth exploring further,” Julian humorously tweeted. “Might be interesting to consider what happens if the cloud gets so light that it floats away.” To which I replied that if the cloud gets so light that it floats away, it could become Interstellar Computing or, as Julian suggested, the start of the Intergalactic Net, which I suppose is where we will eventually have to store all of that big data we keep hearing so much about these days.
The third thing I demonstrated was the potential dark side of data cleansing, since the only remaining trace of my data defect is a broken URL. This is an example of not providing a well-documented audit trail, which is necessary within an organization to communicate data quality issues and resolutions.
Communication and collaboration are essential to finding our way with data quality. And social media can help us by providing more immediate and expanded access to our collective knowledge, experience, and wisdom, and by shining a social light that illuminates the shadows cast upon data quality issues when a perception filter or bystander effect gets the better of our individual attention or undermines our collective best intentions — which, as I recently demonstrated, occasionally happens to all of us.
Data Quality and the Cupertino Effect
Are you turning Ugly Data into Cute Information?
The Wisdom of the Social Media Crowd
Perception Filters and Data Quality
Data Quality and the Bystander Effect
The Family Circus and Data Quality
Metadata, Data Quality, and the Stroop Test

The recent #GartnerChat on Big Data was an excellent Twitter discussion about what I often refer to as the Seven Letter Tsunami of the data management industry, which as Gartner Research explains, although the term acknowledges the exponential growth, availability, and use of information in today’s data-rich landscape, big data is about more than just data volume. Data variety (i.e., structured, semi-structured, and unstructured data, as well as other types, such as the sensor data emanating from the Internet of Things), and data velocity (i.e., how fast data is produced and how fast data must be processed to meet demand) are also key characteristics of the big challenges associated with the big buzzword that big data has become over the last year.
Since ours is an industry infatuated with buzzwords, Timo Elliott remarked “new terms arise because of new technology, not new business problems. Big Data came from a need to name Hadoop [and other technologies now being relentlessly marketed as big data solutions], so anybody using big data to refer to business problems is quickly going to tie themselves in definitional knots.”
To which Mark Troester responded, “the hype of Hadoop is driving pressure on people to keep everything — but they ignore the difficulty in managing it.” John Haddad then quipped that “big data is a hoarders dream,” which prompted Andy Bitterer to coin the term HoardaByte for measuring big data, and then asking, “Would the real Big Data Lebowski please stand up?”
Although it’s probably no surprise that a blogger with obsessive-compulsive in the title of his blog would like Bitterer’s new term, the fact is that whether you choose to measure it in terabytes, petabytes, exabytes, HoardaBytes, or how much reality bitterly bites, our organizations have been compulsively hoarding data for a long time.
And with silos replicating data as well as new data, and new types of data, being created and stored on a daily basis, managing all of the data is not only becoming impractical, but because we are too busy with the activity of trying to manage all of it, we are hoarding countless bytes of data without evaluating data usage, gathering data requirements, or planning for data archival.
In The Big Lebowski, Jeff Lebowski (“The Dude”) is, in a classic data quality blunder caused by matching on person name only, mistakenly identified as millionaire Jeffrey Lebowski (“The Big Lebowski”) in an eccentric plot expected from a Coen brothers film, which, since its release in the late 1990s, has become a cult classic and inspired a religious following known as Dudeism.
Historically, a big part of the problem in our industry has been the fact that the word “data” is prevalent in the names we have given industry disciplines and enterprise information initiatives. For example, data architecture, data quality, data integration, data migration, data warehousing, master data management, and data governance — to name but a few.
However, all this achieved was to perpetuate the mistaken identification of data management as an esoteric technical activity that played little more than a minor, supporting, and often uncredited, role within the business activities of our organizations.
But since the late 1990s, there has been a shift in the perception of data. The real data deluge has not been the rising volume, variety, and velocity of data, but instead the rising awareness of the big impact that data has on nearly every aspect of our professional and personal lives. In this brave new data world, companies like Google and Facebook have built business empires mostly out of our own personal data, which is why, like it or not, as individuals, we must accept that we are all data geeks now.
All of the hype about Big Data is missing the point. The reality is that Data is Big — meaning that data has now so thoroughly pervaded mainstream culture that data has gone beyond being just a cult classic for the data management profession, and is now inspiring an almost religious following that we could call Dataism.
“The Dude abides. I don’t know about you, but I take comfort in that,” remarked The Stranger in The Big Lebowski.
The Data must also abide. And the Data must abide both the Business and the Individual. The Data abides the Business if data proves useful to our business activities. The Data abides the Individual if data protects the privacy of our personal activities.
The Data abides. I don’t know about you, but I would take more comfort in that than in any solutions The Stranger Salesperson wants to sell me that utilize an eccentric sales pitch involving HoardaBytes and the Big Data Lebowski.

One of the many things I love about Twitter is its ability to spark ideas via real-time conversations. For example, while live-tweeting during last week’s episode of DM Radio, the topic of which was how to get started with data governance, I tweeted about the data silo challenges and corporate cultural obstacles being discussed.
I tweeted that data is an asset only if it is a shared asset, across the silos, across the corporate culture, and that, in order to be successful with data governance, organizations must replace the mantra “my private knowledge is my power” with “our shared knowledge empowers us all.”
“That’s very socialist thinking,” Mark Madsen responded. “Soon we’ll be having arguments about capitalizing over socializing our data.”
To which I responded that the more socialized data is, the more capitalized data can become . . . just ask Google.
“Oh no,” Mark humorously replied, “decades of political rhetoric about socialism to be ruined by a discussion of data!” And I quipped that discussions about data have been accused of worse, and decades of data rhetoric certainly hasn’t proven very helpful in corporate politics.
Later, while ruminating on this light-hearted exchange, I wondered if we actually are in the midst of the Data Cold War.
The Cold War, which lasted approximately from 1946 to 1991, was the political, military, and economic competition between the Communist World, primarily the former Soviet Union, and the Western world, primarily the United States. One of the major tenets of the Cold War was the conflicting ideologies of socialism and capitalism.
In enterprise data management, one of the most debated ideologies is whether or not data should be viewed as a corporate asset, especially by the for-profit corporations of capitalism, which is (even before the Cold War began), and will likely forever remain, the world’s dominant economic model.
My earlier remark that data is an asset only if it is a shared asset, across the silos, across the corporate culture, is indicative of the bounded socialist view of enterprise data. In other words, almost no one in the enterprise data management space is suggesting that data should be shared beyond the boundary of the organization. In this sense, advocates, including myself, of data governance are advocating socializing data within the enterprise so that data can be better capitalized as a true corporate asset.
This mindset makes sense because sharing data with the world, especially for free, couldn’t possibly be profitable — or could it?
The genius (and some justifiably ponder if it’s evil genius) of companies like Google and Facebook is they realized how to make money in a free world — by which I mean the world of Free: The Future of a Radical Price, the 2009 book by Chris Anderson.
By encouraging their users to freely share their own personal data, Google and Facebook ingeniously answer what David Loshin calls the most dangerous question in data management: What is the definition of customer?
How do Google and Facebook answer the most dangerous question?
A customer is a product.
This is the first step that begins what I call the Master Data Management Magic Trick.
Instead of trying to manage the troublesome master data domain of customer and link it, through sales transaction data, to the master data domain of product (products, by the way, have always been undeniably accepted as a corporate asset even though product data has not been), Google and Facebook simply eliminate the need for customers (and, by extension, eliminate the need for customer service because, since their product is free, it has no customers) by transforming what would otherwise be customers into the very product that they sell — and, in fact, the only “real” product that they have.
And since what their users perceive as their product is virtual (i.e., entirely Internet-based), it’s not really a product, but instead a free service, which can be discontinued at any time. And if it was, who would you complain to? And on what basis?
After all, you never paid for anything.
This is the second step that completes the Master Data Management Magic Trick — a product is a free service.
Therefore, Google and Facebook magically make both their customers and their products (i.e., master data) disappear, while simultaneously making billions of dollars (i.e., transaction data) appear in their corporate bank accounts.
(Yes, the personal data of their users is master data. However, because it is used in an anonymized and aggregated format, it is not, nor does it need to be, managed like the master data we talk about in the enterprise data management industry.)
By “empowering” us with free services, Google and Facebook use the power of our own personal data against us — by selling it.
However, it’s important to note that they indirectly sell our personal data as anonymized and aggregated demographic data.
Although they do not directly sell our individually identifiable information (because, truthfully, it has very limited, and mostly no legal, value, i.e., that would be identity theft), Google and Facebook do occasionally get sued (mostly outside the United States) for violating data privacy and data protection laws.
However, it’s precisely because we freely give our personal data to them, that until, or if, laws are changed to protect us from ourselves, it’s almost impossible to prove they are doing anything illegal (again, their undeniable genius is arguably evil genius).
Google and Facebook are the exact same kind of company — they are both Internet advertising agencies.
They both sell online advertising space to other companies, which are looking to demographically target prospective customers because those companies actually do view people as potential real customers for their own real products.
The irony is that if all of their users stopped using their free service, then not only would our personal data be more private and more secure, but the new revenue streams of Google and Facebook would eventually dry up because, specifically by design, they have neither real customers nor real products. More precisely, their only real customers (other companies) would stop buying advertising from them because no one would ever see and (albeit, even now, only occasionally) click on their ads.
Essentially, companies like Google and Facebook are winning the Data Cold War because they have capitalized socialism.
In other words, the bottom line is Google and Facebook have socialized data in order to capitalize data as a true corporate asset.
Freemium is the future – and the future is now
Amazon’s Data Management Brain

Sometimes the ways of the data force are difficult to understand precisely because they are sometimes difficult to see.
Daragh O Brien and I were discussing this recently on Twitter, where tweets about data quality and information quality form the midi-chlorians of the data force. Share disturbances you’ve felt in the data force using the #UglyData and #CuteInfo hashtags.
Perhaps one of the most common examples of the difference between data and information is the presentation layer created for business users. In her fantastic book Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information, Danette McGilvray defines Presentation Quality as “a measure of how information is presented to, and collected from, those who utilize it. Format and appearance support appropriate use of the information.”
Tom Redman emphasizes the two most important points in the data lifecycle are when data is created and when data is used.
I describe the connection between those two points as the Data-Information Bridge. By passing over this bridge, data becomes the information used to make the business decisions that drive the tactical and strategic initiatives of the organization. Some of the most important activities of enterprise data management actually occur on the Data-Information Bridge, where preventing critical disconnects between data creation and data usage is essential to the success of the organization’s business activities.
Defect prevention and data cleansing are two of the required disciplines of an enterprise-wide data quality program. Defect prevention is focused on the moment of data creation, attempting to enforce better controls to prevent poor data quality at the source. Data cleansing can either be used to compensate for a lack of defect prevention, or it can be included in the processing that prepares data for a specific use (i.e., transforms data into information fit for the purpose of a specific business use.)
In a previous post, I explained that although most organizations acknowledge the importance of data quality, they don’t believe that data quality issues occur very often because the information made available to end users in dashboards and reports often passes through many processes that cleanse or otherwise sanitize the data before it reaches them.
ETL processes that extract source data for a data warehouse load will often perform basic data quality checks. However, a fairly standard practice for “resolving” a data quality issue is to substitute either a missing or default value (e.g., a date stored in a text field in the source, which can not be converted into a valid date value, is loaded with either a NULL value or the processing date).
When postal address validation software generates a valid mailing address, it often does so by removing what it considers to be “extraneous” information from input address fields, which may include valid data accidentally entered in the wrong field, or that was lacking its own input field (e.g., e-mail address in an input address field deleted from the output valid mailing address).
And some reporting processes intentionally filter out “bad records” or eliminate “outlier values.” This happens most frequently when preparing highly summarized reports, especially those intended for executive management.
These are just a few examples of the Dark Side of Data Cleansing, which can turn Ugly Data into Cute Information.
Like truth, beauty, and singing ability, data quality is in the eyes of the beholder, or since data quality is most commonly defined as fitness for the purpose of use, we could say that data quality is in the eyes of the user. But how do users know if data is truly fit for their purpose, or if they are simply being presented with information that is aesthetically pleasing for their purpose?
Has your data quality turned to the dark side by turning ugly data into cute information?
Data, Information, and Knowledge Management
Beyond a “Single Version of the Truth”
The Data-Information Continuum
Data Quality and the Cupertino Effect
OCDQ Radio - Organizing for Data Quality
Amazon’s Data Management Brain
Holistic Data Management (Part 3)
Holistic Data Management (Part 2)
Holistic Data Management (Part 1)
OCDQ Radio - Data Governance Star Wars
OCDQ Radio is a vendor-neutral podcast about data quality and its related disciplines, produced and hosted by Jim Harris.
Phil Simon is the author of three books: The New Small (Motion, 2010), Why New Systems Fail (Cengage, 2010) and The Next Wave of Technologies (John Wiley & Sons, 2010).
A recognized technology expert, he consults companies on how to optimize their use of technology. His contributions have been featured on The Globe and Mail, the American Express Open Forum, ComputerWorld, ZDNet, abcnews.com, forbes.com, The New York Times, ReadWriteWeb, and many other sites.
When not fiddling with computers, hosting podcasts, putting himself in comics, and writing, Phil enjoys English Bulldogs, tennis, golf, movies that hurt the brain, fantasy football, and progressive rock—which is also the subject of this episode’s book contest (see below).
On this episode of OCDQ Radio, Phil and I discuss his fourth book, The Age of the Platform, which will be published later this year thanks to the help of the generous contributions of people like you who are backing the book’s Kickstarter project.
Clicking on the link will take you to the episode’s blog post:
OCDQ Radio is a vendor-neutral podcast about data quality and its related disciplines, produced and hosted by Jim Harris.
Effectively using social media within a business context is more art than science, which is why properly planning and executing a social media strategy is essential for organizations as well as individual professionals.
On this episode, I discuss social media strategy and content marketing with Crysta Anderson, a Social Media Strategist for IBM, who manages IBM InfoSphere’s social media presence, including the Mastering Data Management blog, the @IBMInitiate and @IBM_InfoSphere Twitter accounts, LinkedIn and other platforms.
Crysta Anderson also serves as a social media subject matter expert for IBM’s Information Management division.
Under Crysta’s execution, IBM Initiate has received numerous social media awards, including “Best Corporate Blog” from the Chicago Business Marketing Association, Marketing Sherpa’s 2010 Viral and Social Marketing Hall of Fame, and BtoB Magazine’s list of “Most Successful Online Social Networking Initiatives.”
Crysta graduated from the University of Chicago with a BA in Political Science and is currently pursuing a Master’s in Integrated Marketing Communications at Northwestern University’s Medill School. Learn more about Crysta Anderson on LinkedIn.
Clicking on the link will take you to the episode’s blog post:
As Alice Hardy arrived at her desk at Crystal Lake Insurance, it seemed like a normal Friday morning. Her thoughts about her weekend camping trip were interrupted by an eerie sound emanating from one of the adjacent cubicles:
Da da da, ta ta ta. Da da da, ta ta ta.
“What’s that sound?” Alice wondered out loud.
“Sorry, am I typing too loud again?” responded Tommy Jarvis from another adjacent cubicle. “Can you come take a look at something for me?”
“Sure, I’ll be right over,” Alice replied as she quickly circumnavigated their cluster of cubicles, puzzled and unsettled to find the other desks unoccupied with their computers turned off, wondering, to herself this time, where did that eerie sound come from? Where are the other data counselors today?
“What’s up?” she casually asked upon entering Tommy’s cubicle, trying, as always, to conceal her discomfort about being alone in the office with the one colleague that always gave her the creeps. Visiting his cubicle required a constant vigilance in order to avoid making prolonged eye contact, not only with Tommy Jarvis, but also with the horrifying hockey mask hanging above his computer screen like some possessed demon spawn from a horror movie.
“I’m analyzing the Date of Death in the life insurance database,” Tommy explained. “And I’m receiving really strange results. First of all, there are no NULLs, which indicates all of our policyholders are dead, right? And if that wasn’t weird enough, there are only 12 unique values: January 13, 1978, February 13, 1981, March 13, 1987, April 13, 1990, May 13, 2011, June 13, 1997, July 13, 2001, August 13, 1971, September 13, 2002, October 13, 2006, November 13, 2009, and December 13, 1985.”
“That is strange,” said Alice. “All of our policyholders can’t be dead. And why is Date of Death always the 13th of the month?”
“It’s not just always the 13th of the month,” Tommy responded, almost cheerily. “It’s always a Friday the 13th.”
“Well,” Alice slowly, and nervously, replied. “I have a life insurance policy with Crystal Lake Insurance. Pull up my policy.”
After a few, quick, loud pounding keystrokes, Tommy ominously read aloud the results now displaying on his computer screen, just below the hockey mask that Alice could swear was staring at her. “Date of Death: May 13, 2011 . . . Wait, isn’t that today?”
Da da da, ta ta ta. Da da da, ta ta ta.
“Did you hear that?” asked Alice. “Hear what?” responded Tommy with a devilish grin.
“Never mind,” replied Alice quickly while trying to focus her attention on only the computer screen. “Are you sure you pulled up the right policy? I don’t recognize the name of the Primary Beneficiary . . . Who the hell is Jason Voorhees?”
“How the hell could you not know who Jason Voorhees is?” asked Tommy, with anger sharply crackling throughout his words. “Jason Voorhees is now rightfully the sole beneficiary of every life insurance policy ever issued by Crystal Lake Insurance.”
Da da da, ta ta ta. Da da da, ta ta ta.
“What? That’s impossible!” Alice screamed. “This has to be some kind of sick data quality joke.”
“It’s a data quality masterpiece!” Tommy retorted with rage. “I just finished implementing my data machete, er I mean, my data matching solution. From now on, Crystal Lake Insurance will never experience another data quality issue.”
“There’s just one last thing that I need to take care of.”
Da da da, ta ta ta. Da da da, ta ta ta.
“And what’s that?” Alice asked, smiling nervously while quickly backing away into the hallway—and preparing to run for her life.
Da da da, ta ta ta. Da da da, ta ta ta.
“Real-world alignment,” replied Tommy. Rising to his feet, he put on the hockey mask, and pulled an actual machete out of the bottom drawer of his desk. “Your Date of Death is entered as May 13, 2011. Therefore, I must ensure real-world alignment.”
Da da da, ta ta ta. Da da da, ta ta ta. Da da da, ta ta ta. Da da da, ta ta ta. Data Quality.
The End.
(Note — You can also listen to the OCDQ Radio Theater production of this DQ-Tale in the Scary Calendar Effects episode.)
#FollowFriday is when Twitter users recommend other users you should follow, so here are some great tweeps who provide tweets mostly about Data Quality, Data Governance, Master Data Management, Business Intelligence, and Big Data Analytics:
(Please Note: This is by no means a comprehensive list, is listed in no particular order whatsoever, and no offense is intended to any of my tweeps not listed below. I hope that everyone has a great #FollowFriday and an even greater weekend.)
|
|
I have previously blogged in defense of Twitter, the pithy platform for social networking that I use perhaps a bit too frequently, and about which many people argue is incompatible with meaningful communication (Twitter that is, not me—hopefully).
Whether it is a regularly scheduled meeting of the minds, like the Data Knights Tweet Jam, or simply a spontaneous supply of trenchant thoughts, Twitter quite often facilitates discussions that deliver practical knowledge or thought-provoking theories.
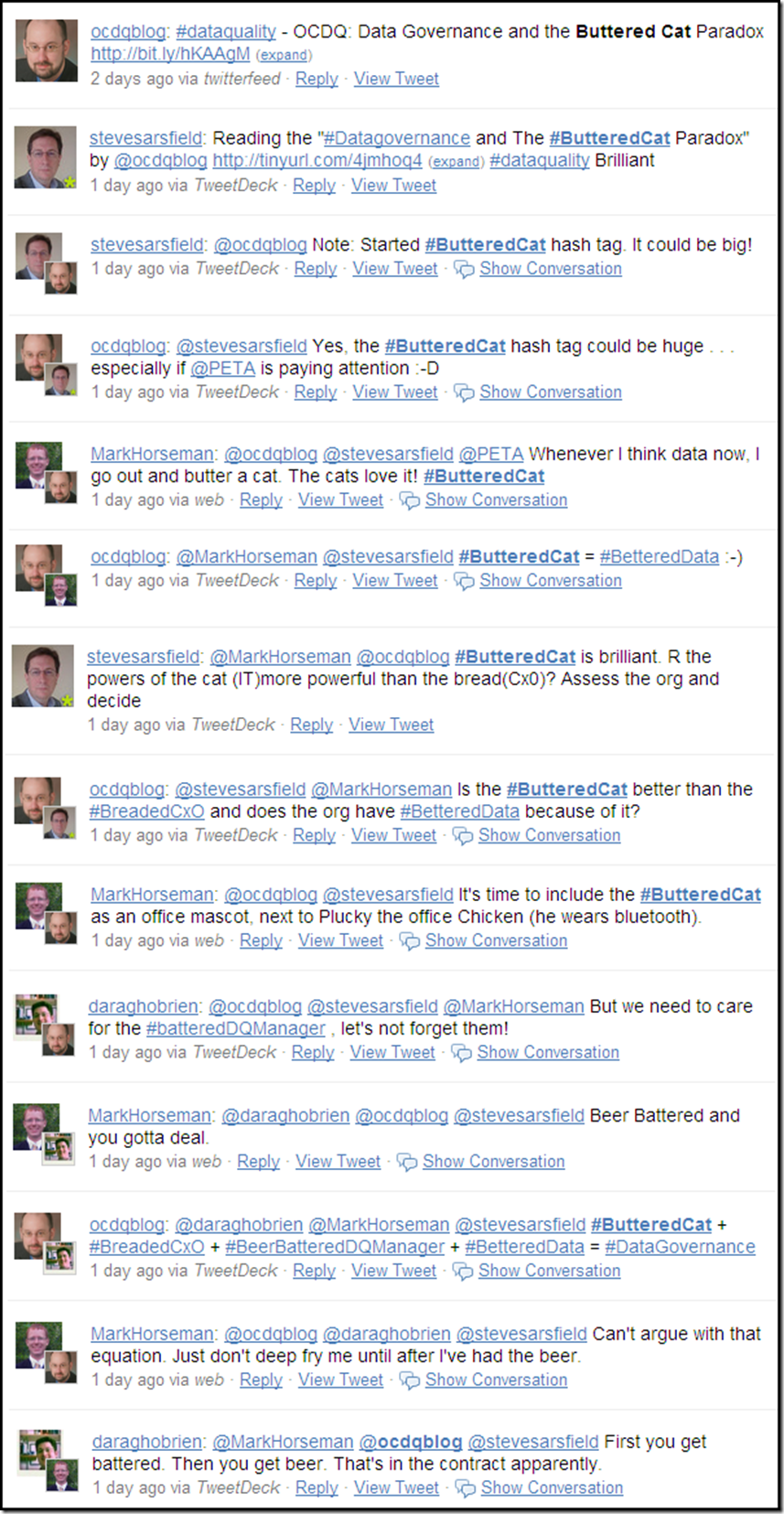
However, occasionally the discussions center around more curious concepts, such as a paradox involving a buttered cat, which thankfully Steve Sarsfield, Mark Horseman, and Daragh O Brien can help me attempt to explain (remember I said attempt):
So, basically . . . successful data governance is all about Buttered Cats, Breaded CxOs, and Beer-Battered Data Quality Managers working together to deliver Bettered Data to the organization . . . yeah, that all sounded perfectly understandable to me.
But just in case you don’t have your secret decoder ring, let’s decipher the message (remember: “Be sure to drink your Ovaltine”):
(For more slightly less cryptic information, check out my previous post/poll: Data Governance and the Buttered Cat Paradox)
Today is #FollowFriday, the day when Twitter users recommend other users you should follow, so here are some great tweeps for mostly non-buttered-cat tweets about Data Quality, Data Governance, Master Data Management, and Business Intelligence:
(Please Note: This is by no means a comprehensive list, is listed in no particular order whatsoever, and no offense is intended to any of my tweeps not listed below. I hope that everyone has a great #FollowFriday and an even greater weekend.)
|
|
#FollowFriday Spotlight: @PhilSimon
#FollowFriday Spotlight: @hlsdk
#FollowFriday Spotlight: @DataQualityPro
#FollowFriday and The Three Tweets
Dilbert, Data Quality, Rabbits, and #FollowFriday
Twitter, Meaningful Conversations, and #FollowFriday
The Fellowship of #FollowFriday
The Wisdom of the Social Media Crowd
Social Karma (Part 7) – Twitter
FollowFriday Spotlight is an OCDQ regular segment highlighting someone you should follow—and not just Fridays on Twitter.
 |
Phil Simon is an independent technology consultant, author, writer, and dynamic public speaker for hire, who focuses on the intersection of business and technology. Phil is the author of three books (see below for more details) and also writes for a number of technology media outlets and sites, and hosts the podcast Technology Today.
As an independent consultant, Phil helps his clients optimize their use of technology. Phil has cultivated over forty clients in a wide variety of industries, including health care, manufacturing, retail, education, telecommunications, and the public sector.
When not fiddling with computers, hosting podcasts, putting himself in comics, and writing, Phil enjoys English Bulldogs, tennis, golf, movies that hurt the brain, fantasy football, and progressive rock. Phil is a particularly zealous fan of Rush, Porcupine Tree, and Dream Theater. Anyone who reads his blog posts or books will catch many references to these bands.
 |
My review of The New Small: By leveraging what Phil Simon calls the Five Enablers (Cloud computing, Software-as-a-Service (SaaS), Free and open source software (FOSS), Mobility, Social technologies), small businesses no longer need to have technology as one of their core competencies, nor invest significant time and money in enabling technology, which allows them to focus on their true core competencies and truly compete against companies of all sizes. The New Small serves as a practical guide to this brave new world of small business. |
 |
My review of The Next Wave of Technologies: The constant challenge faced by organizations, large and small, which are using technology to support the ongoing management of their decision-critical information, is that the business world of information technology can never afford to remain static, but instead, must dynamically evolve and adapt, in order to protect and serve the enterprise’s continuing mission to survive and thrive in today’s highly competitive and rapidly changing marketplace.
|
 |
My review of Why New Systems Fail: Why New Systems Fail is far from a doom and gloom review of disastrous projects and failed system implementations. Instead, this book contains numerous examples and compelling case studies, which serve as a very practical guide for how to recognize, and more importantly, overcome the common mistakes that can prevent new systems from being successful. Phil Simon writes about these complex challenges in a clear and comprehensive style that is easily approachable and applicable to diverse audiences, both academic and professional, as well as readers with either a business or a technical orientation. |
In addition to his great books, Phil is a great blogger. For example, check out these brilliant blog posts written by Phil Simon:
 |
Phil Simon and I co-host and co-produce the wildly popular podcast Knights of the Data Roundtable, a bi-weekly data management podcast sponsored by the good folks at DataFlux, a SAS Company. The podcast is a frank and open discussion about data quality, data integration, data governance and all things related to managing data. |
#FollowFriday Spotlight: @hlsdk
#FollowFriday Spotlight: @DataQualityPro
#FollowFriday and Re-Tweet-Worthiness
#FollowFriday and The Three Tweets
Dilbert, Data Quality, Rabbits, and #FollowFriday
Twitter, Meaningful Conversations, and #FollowFriday
The Fellowship of #FollowFriday
Social Karma (Part 7) – Twitter
Obsessive-Compulsive Data Quality (OCDQ) is a blog offering a vendor-neutral perspective on data quality and its related disciplines.
| Home | Blog | Podcast | Videos | Best of OCDQ | Published Articles | About | Contact |
|
© 2022, Jim Harris. |
Powered by Squarespace |