The recent #GartnerChat on Big Data was an excellent Twitter discussion about what I often refer to as the Seven Letter Tsunami of the data management industry, which as Gartner Research explains, although the term acknowledges the exponential growth, availability, and use of information in today’s data-rich landscape, big data is about more than just data volume. Data variety (i.e., structured, semi-structured, and unstructured data, as well as other types, such as the sensor data emanating from the Internet of Things), and data velocity (i.e., how fast data is produced and how fast data must be processed to meet demand) are also key characteristics of the big challenges associated with the big buzzword that big data has become over the last year.
Since ours is an industry infatuated with buzzwords, Timo Elliott remarked “new terms arise because of new technology, not new business problems. Big Data came from a need to name Hadoop [and other technologies now being relentlessly marketed as big data solutions], so anybody using big data to refer to business problems is quickly going to tie themselves in definitional knots.”
To which Mark Troester responded, “the hype of Hadoop is driving pressure on people to keep everything — but they ignore the difficulty in managing it.” John Haddad then quipped that “big data is a hoarders dream,” which prompted Andy Bitterer to coin the term HoardaByte for measuring big data, and then asking, “Would the real Big Data Lebowski please stand up?”
HoardaBytes
Although it’s probably no surprise that a blogger with obsessive-compulsive in the title of his blog would like Bitterer’s new term, the fact is that whether you choose to measure it in terabytes, petabytes, exabytes, HoardaBytes, or how much reality bitterly bites, our organizations have been compulsively hoarding data for a long time.
And with silos replicating data as well as new data, and new types of data, being created and stored on a daily basis, managing all of the data is not only becoming impractical, but because we are too busy with the activity of trying to manage all of it, we are hoarding countless bytes of data without evaluating data usage, gathering data requirements, or planning for data archival.
The Big Data Lebowski
In The Big Lebowski, Jeff Lebowski (“The Dude”) is, in a classic data quality blunder caused by matching on person name only, mistakenly identified as millionaire Jeffrey Lebowski (“The Big Lebowski”) in an eccentric plot expected from a Coen brothers film, which, since its release in the late 1990s, has become a cult classic and inspired a religious following known as Dudeism.
Historically, a big part of the problem in our industry has been the fact that the word “data” is prevalent in the names we have given industry disciplines and enterprise information initiatives. For example, data architecture, data quality, data integration, data migration, data warehousing, master data management, and data governance — to name but a few.
However, all this achieved was to perpetuate the mistaken identification of data management as an esoteric technical activity that played little more than a minor, supporting, and often uncredited, role within the business activities of our organizations.
But since the late 1990s, there has been a shift in the perception of data. The real data deluge has not been the rising volume, variety, and velocity of data, but instead the rising awareness of the big impact that data has on nearly every aspect of our professional and personal lives. In this brave new data world, companies like Google and Facebook have built business empires mostly out of our own personal data, which is why, like it or not, as individuals, we must accept that we are all data geeks now.
All of the hype about Big Data is missing the point. The reality is that Data is Big — meaning that data has now so thoroughly pervaded mainstream culture that data has gone beyond being just a cult classic for the data management profession, and is now inspiring an almost religious following that we could call Dataism.
The Data must Abide
“The Dude abides. I don’t know about you, but I take comfort in that,” remarked The Stranger in The Big Lebowski.
The Data must also abide. And the Data must abide both the Business and the Individual. The Data abides the Business if data proves useful to our business activities. The Data abides the Individual if data protects the privacy of our personal activities.
The Data abides. I don’t know about you, but I would take more comfort in that than in any solutions The Stranger Salesperson wants to sell me that utilize an eccentric sales pitch involving HoardaBytes and the Big Data Lebowski.
Related Posts

 Over the weekend, in preparation for watching the Boston Red Sox, I bought some beer and pizza. Later that night, after a thrilling victory that sent the Red Sox to the 2013 World Series, I was cleaning up the kitchen and was about to throw out the receipt when I couldn’t help but notice two data quality issues.
Over the weekend, in preparation for watching the Boston Red Sox, I bought some beer and pizza. Later that night, after a thrilling victory that sent the Red Sox to the 2013 World Series, I was cleaning up the kitchen and was about to throw out the receipt when I couldn’t help but notice two data quality issues.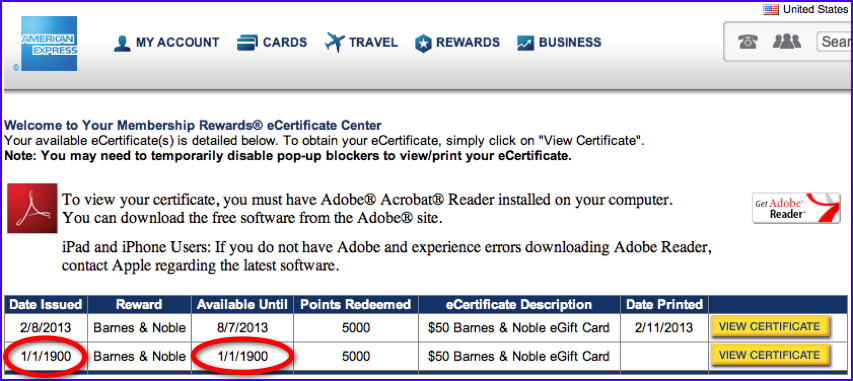


 Last week, when I published my blog post
Last week, when I published my blog post