
Adventures in Data Profiling (Part 6)
/In Part 5 of this series: You completed your initial analysis of the fields relating to postal address with the investigation of Postal Address Line 1 and Postal Address Line 2.
You saw additional examples of why free-form fields are often easier to analyze as formats constructed by parsing and classifying the individual values within the field.
You learned this analysis technique is often necessary since not only is the cardinality of free-form fields usually very high, but they also tend to have a very high Distinctness (i.e. the exact same field value rarely occurs on more than one record).
You also saw examples of how the most frequently occurring formats for free-form fields will often collectively account for a large percentage of the records with an actual value in the field.
In Part 6, you will continue your adventures in data profiling by analyzing the Account Number and Tax ID fields.
Account Number
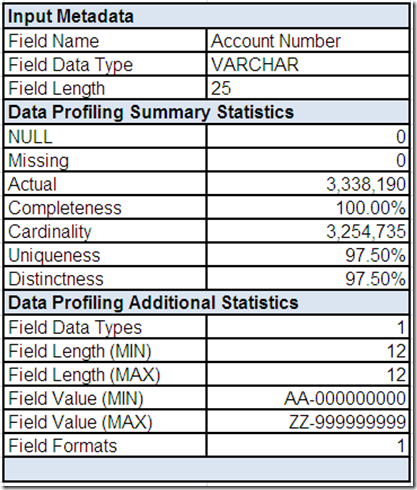
The field summary for Account Number includes input metadata along with the summary and additional statistics provided by the data profiling tool.
In Part 2, we learned that Customer ID is likely an integer surrogate key and the primary key for this data source because it is both 100% complete and 100% unique. Account Number is 100% complete and almost 100% unique. Perhaps it was intended to be the natural key for this data source?
Let's assume that drill-downs revealed the single profiled field data type was VARCHAR and the single profiled field format was aa-nnnnnnnnn (i.e. 2 characters, followed by a hyphen, followed by a 9 digit number).
Combined with the profiled minimum/maximum field lengths, the good news appears to be that not only is Account Number always populated, it is also consistently formatted.
The profiled minimum/maximum field values appear somewhat suspicious, possibly indicating the presence of invalid values?
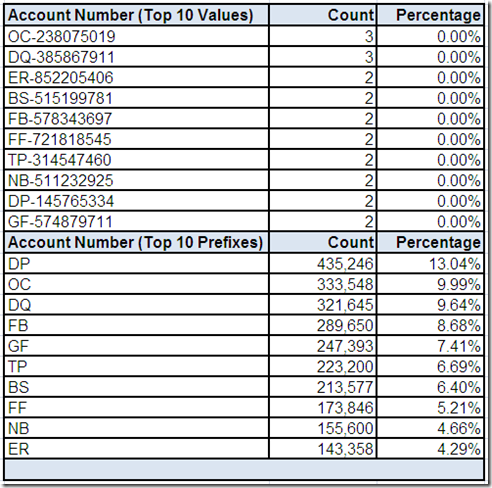
We can use drill-downs on the field summary “screen” to get more details about Account Number provided by the data profiling tool.
The cardinality of Account Number is very high, as is its Distinctness (i.e. the same field value rarely occurs on more than one record). Therefore, when we limit the review to only the top ten most frequently occurring values, it is not surprising to see low counts.
Since we do not yet have a business understanding of the data, we are not sure if it is valid for multiple records to have the same Account Number.
Additional analysis can be performed by extracting the alpha prefix and reviewing its top ten most frequently occurring values. One aspect of this analysis is that it can be used to assess the possibility that Account Number is an “intelligent key.” Perhaps the alpha prefix is a source system code?
Tax ID
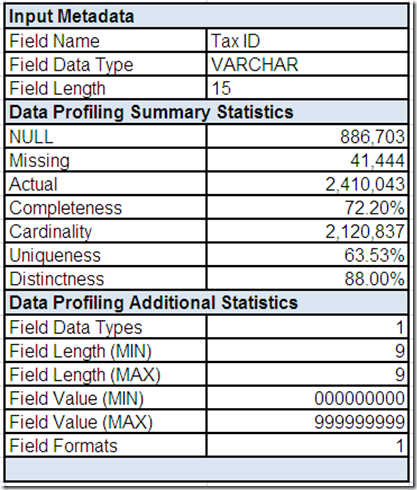
The field summary for Tax ID includes input metadata along with the summary and additional statistics provided by the data profiling tool.
Let's assume that drill-downs revealed the single profiled field data type was INTEGER and the single profiled field format was nnnnnnnnn (i.e. a 9 digit number).
Combined with the profiled minimum/maximum field lengths, the good news appears to be that Tax ID is also consistently formatted. However, the profiled minimum/maximum field values appear to indicate the presence of invalid values.
In Part 4, we learned that most of the records appear to have either an United States (US) or Canada (CA) postal address. For US records, the Tax ID field could represent the social security number (SSN), federal employer identification number (FEIN), or tax identification number (TIN). For CA records, this field could represent the social insurance number (SIN). All of these identifiers are used for tax reporting purposes and have a 9 digit number format (when no presentation formatting is used).
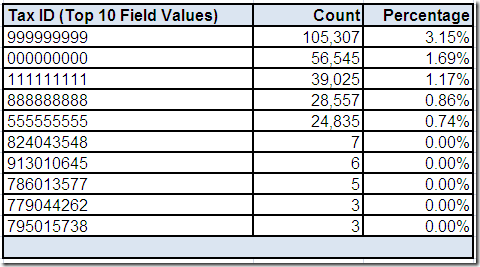
We can use drill-downs on the field summary “screen” to get more details about Tax ID provided by the data profiling tool.
The Distinctness of Tax ID is slightly lower than Account Number and therefore the same field value does occasionally occur on more than one record.
Since the cardinality of Tax ID is very high, we will limit the review to only the top ten most frequently occurring values. This analysis reveals the presence of more (most likely) invalid values.
Potential Duplicate Records
In Part 1, we asked if the data profiling statistics for Account Number and/or Tax ID indicate the presence of potential duplicate records. In other words, since some distinct actual values for these fields occur on more than one record, does this imply more than just a possible data relationship, but a possible data redundancy? Obviously, we would need to interact with the business team in order to better understand the data and their business rules for identifying duplicate records.
However, let's assume that we have performed drill-down analysis using the data profiling tool and have selected the following records of interest:
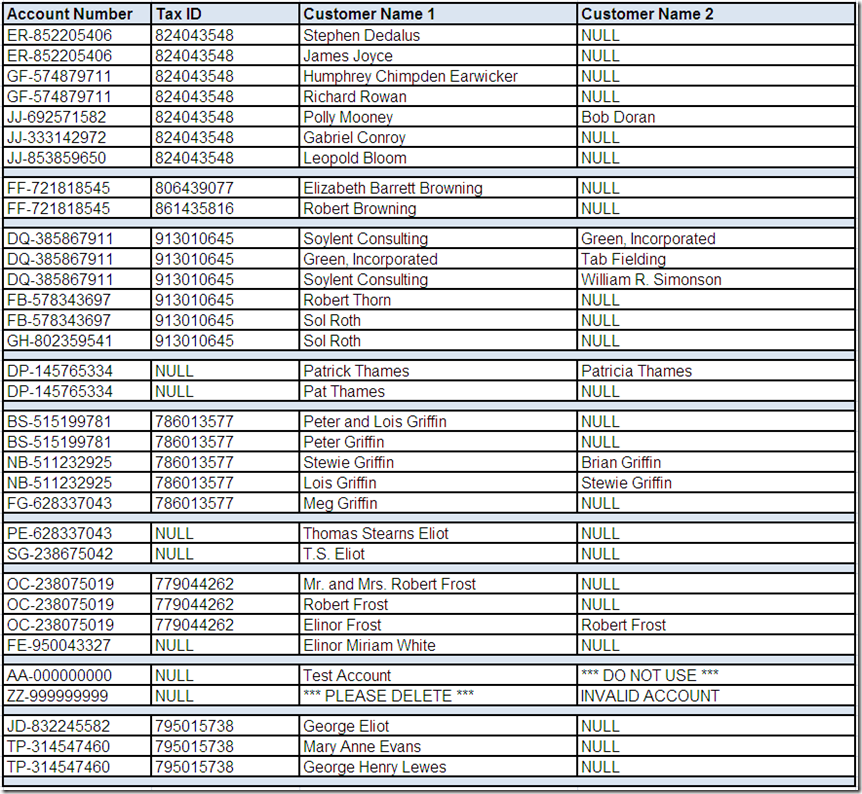
What other analysis do you think should be performed for these fields?
In Part 7 of this series: We will continue the adventures in data profiling by completing our initial analysis with the investigation of the Customer Name 1 and Customer Name 2 fields.
Related Posts
Adventures in Data Profiling (Part 1)
Adventures in Data Profiling (Part 2)
Adventures in Data Profiling (Part 3)
Adventures in Data Profiling (Part 4)
Adventures in Data Profiling (Part 5)
Adventures in Data Profiling (Part 7)

