
What Data Quality Technology Wants
/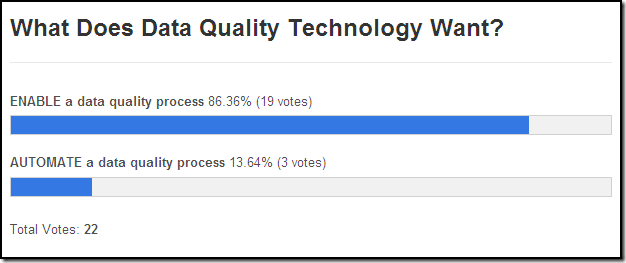
This is a screen capture of the results of last month’s unscientific data quality poll where it was noted that viewpoints about the role of data quality technology (i.e., what data quality technology wants) are generally split between two opposing perspectives:
- Technology enables a data quality process, but doesn’t obviate the need for people (e.g., data stewards) to remain actively involved and be held accountable for maintaining the quality of data.
- Technology automates a data quality process, and a well-designed and properly implemented technical solution obviates the need for people to be actively involved after its implementation.
Commendable Comments
Henrik Liliendahl Sørensen voted for enable, but commented he likes to say enables by automating the time consuming parts, an excellent point which he further elaborated on in two of his recent blog posts: Automation and Technology and Maturity.
Garnie Bolling commented that he believes people will always be part of the process, especially since data quality has so many dimensions and trends, and although automated systems can deal with what he called fundamental data characteristics, an automated system can not change with trends or the ongoing evolution of data.
Frank Harland commented that automation can and has to take over the tedious bits of work (e.g., he wouldn't want to type in all those queries that can be automated by data profiling tools), but to get data right, we have to get processes right, get data architecture right, get culture and KPI’s right, and get a lot of the “right” people to do all the hard work that has to be done.
Chris Jackson commented that what an organization really needs is quality data processes not data quality processes, and once the focus is on treating the data properly rather than catching and remediating poor data, you can have a meaningful debate about the relative importance of well-trained and motivated staff vs. systems that encourage good data behavior vs. replacing fallible people with standard automated process steps.
Alexa Wackernagel commented that when it comes to discussions about data migration and data quality with clients, she often gets the requirement—or better to call it the dream—for automated processes, but the reality is that data handling needs easy accessible technology to enable data quality.
Thanks to everyone who voted and special thanks to everyone who commented. As always, your feedback is greatly appreciated.
What Data Quality Technology Wants: Enable and Automate
|
|
|


I have to admit that my poll question was flawed (as my friend HAL would say, “It can only be attributable to human error”).
Posing the question in an either/or context made it difficult for the important role of automation within data quality processes to garner many votes. I agree with the comments above that the role of data quality technology is to both enable and automate.
As the Wonder Twins demonstrate, data quality technology enables Zan (i.e., technical people), Jayna (i.e., business people), and Gleek (i.e., data space monkeys, er I mean, data people) to activate one of their most important powers—collaboration.
In addition to the examples described in the comments above, data quality technology automates proactive defect prevention by providing real-time services, which greatly minimize poor data quality at the multiple points of origin within the data ecosystem, because although it is impossible to prevent every problem before it happens, the more control enforced where data originates, the better the overall enterprise data quality will be—or as my friend HAL would say:
“Putting data quality technology to its fullest possible use is all any corporate entity can ever hope to do.”
Related Posts
What Does Data Quality Technology Want?
DQ-Tip: “Data quality tools do not solve data quality problems...”
Which came first, the Data Quality Tool or the Business Need?
Data Quality Industry: Problem Solvers or Enablers?
The Tooth Fairy of Data Quality
Data Quality is not a Magic Trick
Do you believe in Magic (Quadrants)?
Pirates of the Computer: The Curse of the Poor Data Quality

