Plato’s Data
/Plato’s Cave is a famous allegory from philosophy that describes a fictional scenario where people mistake an illusion for reality.
The allegory describes a group of people who have lived their whole lives as prisoners chained motionless in a dark cave, forced to face a blank wall. Behind the prisoners is a large fire. In front of the fire are puppeteers that project shadows onto the cave wall, acting out little plays, which include mimicking voices and sound effects that echo off the cave walls. These shadows and echoes are only projections, partial reflections of a reality created by the puppeteers. However, this illusion represents the only reality the prisoners have ever known, and so to them the shadows are real sights and the echoes are real sounds.
When one of the prisoners is freed and permitted to turn around and see the source of the shadows and echoes, he rejects reality as an illusion. The prisoner is then dragged out of the cave into the sunlight, out into the bright, painful light of the real world, which he also rejects as an illusion. How could these sights and sounds be real to him when all he has ever known is the cave?
But eventually the prisoner acclimates to the real world, realizing that the real illusion was the shadows and echoes in the cave.
Unfortunately, this is when he’s returned to his imprisonment in the cave. Can you imagine how painful the rest of his life will be, once again being forced to watch the shadows and listen to the echoes — except now he knows that they are not real.
Plato’s Cinema
A modern update on the allegory is something we could call Plato’s Cinema, where a group of people live their whole lives as prisoners chained motionless in a dark cinema, forced to face a blank screen. Behind the audience is a large movie projector.
Please stop reading for a moment and try to imagine if everything you ever knew was based entirely on the movies you watched.
Now imagine you are one of the prisoners, and you did not get to choose the movies, but instead were forced to watch whatever the projectionist chooses to show you. Although the fictional characters and stories of these movies are only projections, partial reflections of a reality created by the movie producers, since this illusion would represent the only reality you have ever known, to you the characters would be real people and the stories would be real events.
If you were freed from this cinema prison, permitted to turn around and see the projector, wouldn’t you reject it as an illusion? If you were dragged out of the cinema into the sunlight, out into the bright, painful light of the real world, wouldn’t you also reject reality as an illusion? How could these sights and sounds be real to you when all you have ever known is the cinema?
Let’s say that you eventually acclimated to the real world, realizing that the real illusion was the projections on the movie screen.
However, now let’s imagine that you are then returned to your imprisonment in the dark cinema. Can you imagine how painful the rest of your life would be, once again being forced to watch the movies — except now you know that they are not real.
Plato’s Data
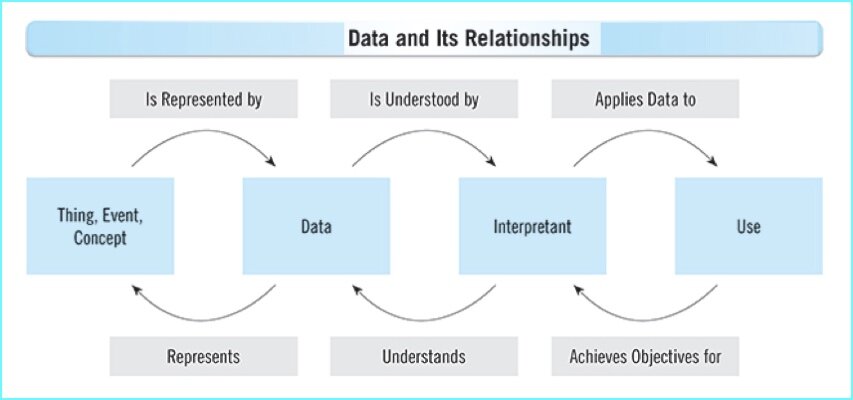
Whether it’s an abstract description of real-world entities (i.e., “master data”) or an abstract description of real-world interactions (i.e., “transaction data”) among entities, data is an abstract description of reality — let’s call this the allegory of Plato’s Data.
We often act as if we are being forced to face our computer screen, upon which data tells us a story about the real world that is just as enticing as the flickering shadows on the wall of Plato’s Cave, or the mesmerizing movies projected in Plato’s Cinema.
Data shapes our perception of the real world, but sometimes we forget that data is only a partial reflection of reality.
I am sure that it sounds silly to point out something so obvious, but imagine if, before you were freed, the other prisoners, in either the cave or the cinema, tried to convince you that the shadows or the movies weren’t real. Or imagine you’re the prisoner returning to either the cave or the cinema. How would you convince other prisoners that you’ve seen the true nature of reality?
A common question about Plato’s Cave is whether it’s crueler to show the prisoner the real world, or to return the prisoner to the cave after he has seen it. Much like the illusions of the cave and the cinema, data makes more sense the more we believe it is real.
However, with data, neither breaking the illusion nor returning ourselves to it is cruel, but is instead a necessary practice because it’s important to occasionally remind ourselves that data and the real world are not the same thing.