
Adventures in Data Profiling (Part 2)
/In Part 1 of this series: The adventures began with the following scenario – You are an external consultant on a new data quality initiative. You have got 3,338,190 customer records to analyze, a robust data profiling tool, half a case of Mountain Dew, it's dark, and you're wearing sunglasses...ok, maybe not those last two or three things – but the rest is true.
You have no prior knowledge of the data or its expected characteristics. You are performing this analysis without the aid of either business requirements or subject matter experts. Your goal is to learn us much as you can about the data and then prepare meaningful questions and reports to share with the rest of your team.
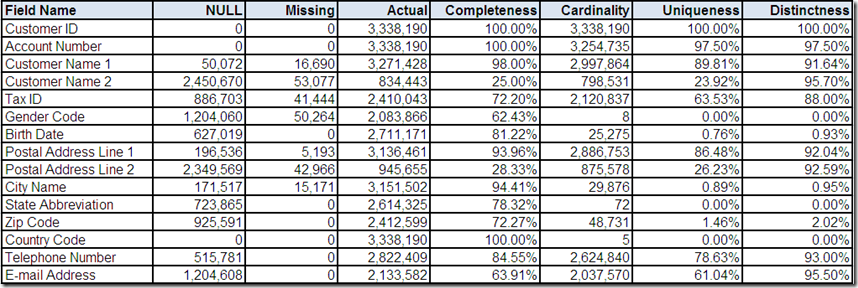
The customer data source was processed by the data profiling tool, which provided the following statistical summaries:
The Adventures Continue...
In Part 1, we asked if Customer ID was the primary key for this data source. In an attempt to answer this question, let's “click” on it and drill-down to a field summary provided by the data profiling tool:
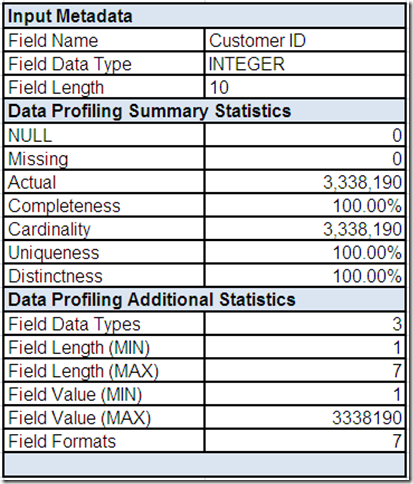
This field summary for Customer ID includes some input metadata, identifying the expected data type and field length. Verifying data matches the metadata that describes it is one essential analytical task that data profiling can help us with, providing a much needed reality check for the perceptions and assumptions that we may have about our data.
The data profiling summary statistics for Customer ID are listed, followed by some useful additional statistics: the count of the number of distinct data types (based on analyzing the values, not the metadata), minimum/maximum field lengths, minimum/maximum field values, and the count of the number of distinct field formats.
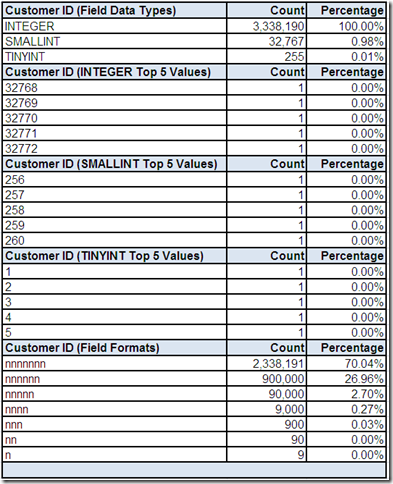
We can use drill-downs on the field summary “screen” to get more details about Customer ID provided by the data profiling tool.
The count of the number of distinct data types is explained by the data profiling tool observing field values that could be represented by three different integer data types based on precision (which can vary by RDBMS). Different tools would represent this in different ways (including the option to automatically collapse the list into the data type of the highest precision that could store all of the values).
Drilling down on the field data types shows the field values (in this example, limited to the 5 most frequently occurring values). Please note, I have intentionally customized these lists to reveal hints about the precision breakdown used by my fictional RDBMS.
The count of the number of distinct field formats shows the frequency distribution of the seven numeric patterns observed by the data profiling tool for Customer ID: 7 digits, 6 digits, 5 digits, 4 digits, 3 digits, 2 digits, and 1 digit. We could also continue drilling down to see the actual field values behind the field formats.
Based on analyzing all of the information provided to you by the data profiling tool, can you safely assume that Customer ID is an integer surrogate key that can be used as the primary key for this data source?
In Part 1, we asked why the Gender Code field has 8 distinct values. Cardinality can play a major role in deciding whether or not you want to drill-down to field values or field formats since it is much easier to review all of the field values when there are not very many of them. Alternatively, the review of high cardinality fields can also be limited to the most frequently occurring values (we will see several examples of this alternative later in the series when analyzing some of the other fields).
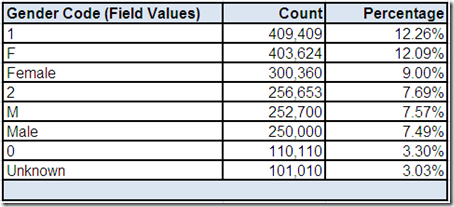
We will drill-down to this “screen” to view the frequency distribution of the field values for Gender Code provided by the data profiling tool.
It is probably not much of a stretch to assume that F is an abbreviation for Female and M is an abbreviation for Male. Also, you may ask if Unknown is any better of a value than NULL or Missing (which are not listed because the list was intentionally filtered to include only Actual values).
However, it is dangerous to assume anything and what about those numeric values? Additionally, you may wonder if Gender Code can tell us anything about the characteristics of the Customer Name fields. For example, do the records with a NULL or Missing value in Gender Code indicate the presence of an organization name and do the records with an Actual Gender Code value indicate the presence of a personal name?
To attempt to answer these questions, it may be helpful to review records with each of these field values. Therefore, let's assume that we have performed drill-down analysis using the data profiling tool and have selected the following records of interest:
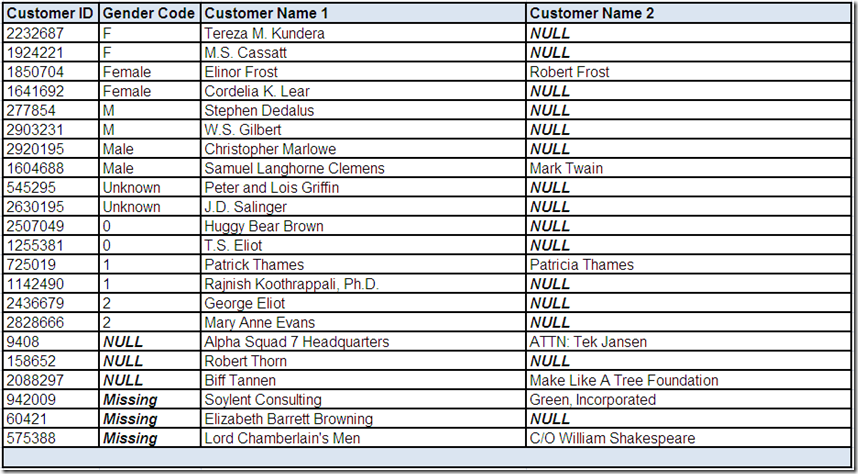
As is so often the case, data rarely conforms to our assumptions about it. Although we will perform more detailed analysis later in the series, what are your thoughts at this point regarding the Gender Code and Customer Name fields?
In Part 3 of this series: We will continue the adventures by using a combination of field values and field formats to begin our analysis of the following fields: Birth Date, Telephone Number and E-mail Address.
Related Posts
Adventures in Data Profiling (Part 1)
Adventures in Data Profiling (Part 3)
Adventures in Data Profiling (Part 4)
Adventures in Data Profiling (Part 5)
Adventures in Data Profiling (Part 6)
Adventures in Data Profiling (Part 7)

