
Adventures in Data Profiling (Part 5)
/In Part 4 of this series: You went totally postal...shifting your focus to postal address by first analyzing the following fields: City Name, State Abbreviation, Zip Code and Country Code.
You learned when a field is both 100% complete and has an extremely low cardinality, its most frequently occurring value could be its default value, how forcing international addresses to be entered into country-specific data structures can cause data quality problems, and with the expert assistance of Graham Rhind, we all learned more about international postal code formats.
In Part 5, you will continue your adventures in data profiling by completing your initial analysis of postal address by investigating the following fields: Postal Address Line 1 and Postal Address Line 2.
Previously, the data profiling tool provided you with the following statistical summaries for postal address:

As we discussed in Part 3 when we looked at the E-mail Address field, most data profiling tools will provide the capability to analyze fields using formats that are constructed by parsing and classifying the individual values within the field.
Postal Address Line 1 and Postal Address Line 2 are additional examples of the necessity of this analysis technique. Not only are the cardinality of these fields very high, but they also have a very high Distinctness (i.e. the exact same field value rarely occurs on more than one record). Some variations in postal addresses can be the results of data entry errors, the use of local conventions, or ignoring (or lacking) postal standards.
Additionally, postal address lines can sometimes contain overflow from other fields (e.g. Customer Name) or they can be used as a dumping ground for values without their own fields (e.g. Twitter username), values unable to conform to the limitations of their intended fields (e.g. countries with something analogous to a US state or CA province but incompatible with a two character field length), or comments (e.g. LDIY, which as Steve Sarsfield discovered, warns us about the Large Dog In Yard).
Postal Address Line 1
The data profiling tool has provided you the following drill-down “screen” for Postal Address Line 1:
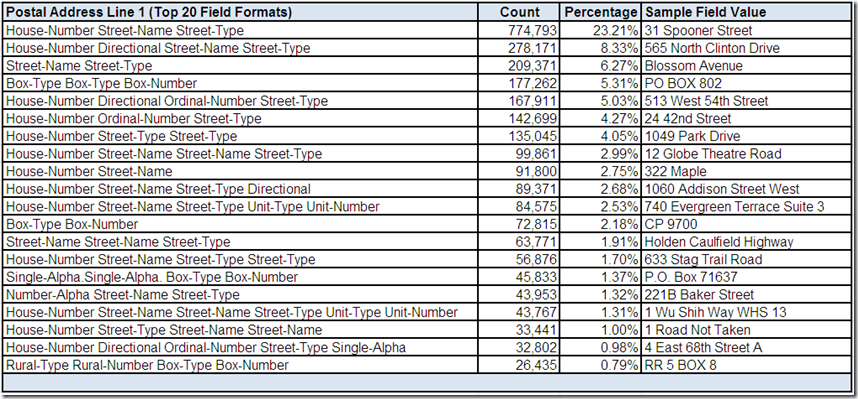
The top twenty most frequently occurring field formats for Postal Address Line 1 collectively account for over 80% of the records with an actual value in this field for this data source. All of these field formats appear to be common potentially valid structures. Obviously, more than one sample field value would need to be reviewed using more drill-down analysis.
What conclusions, assumptions, and questions do you have about the Postal Address Line 1 field?
Postal Address Line 2
The data profiling tool has provided you the following drill-down “screen” for Postal Address Line 2:
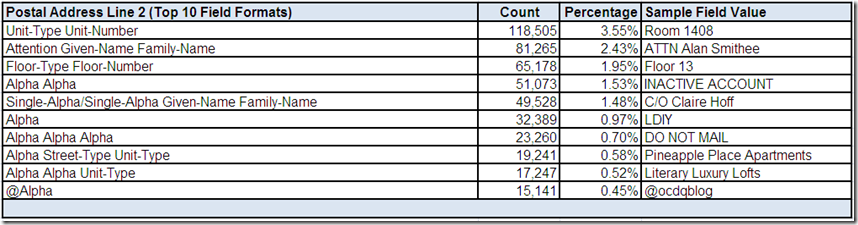
The top ten most frequently occurring field formats for Postal Address Line 2 collectively account for half of the records with an actual value in this sparsely populated field for this data source. Some of these field formats show several common potentially valid structures. Again, more than one sample field value would need to be reviewed using more drill-down analysis.
What conclusions, assumptions, and questions do you have about the Postal Address Line 2 field?
Postal Address Validation
Many data quality initiatives include the implementation of postal address validation software. This provides the capability to parse, identify, verify, and format a valid postal address by leveraging country-specific postal databases.
Some examples of postal validation functionality include correcting misspelled street and city names, populating missing postal codes, and applying (within context) standard abbreviations for sub-fields such as directionals (e.g. N for North and E for East), street types (e.g. ST for Street and AVE for Avenue), and box types (e.g. BP for Boite Postale and CP for Case Postale). These standards not only vary by country, but can also vary within a country when there are multiple official languages.
The presence of non-postal data can sometimes cause either validation failures (i.e. an inability to validate some records, not a process execution failure) or simply deletion of the unexpected values. Therefore, some implementations will use a pre-process to extract the non-postal data prior to validation.
Most validation software will append one or more status fields indicating what happened to the records during processing. It is a recommended best practice to perform post-validation analysis by not only looking at these status fields, but also comparing the record content before and after validation, in order to determine what modifications and enhancements have been performed.
What other analysis do you think should be performed for postal address?
In Part 6 of this series: We will continue the adventures by analyzing the Account Number and Tax ID fields.
Related Posts
Adventures in Data Profiling (Part 1)
Adventures in Data Profiling (Part 2)
Adventures in Data Profiling (Part 3)
Adventures in Data Profiling (Part 4)
Adventures in Data Profiling (Part 6)
Adventures in Data Profiling (Part 7)

