What an Old Dictionary teaches us about Metadata
/
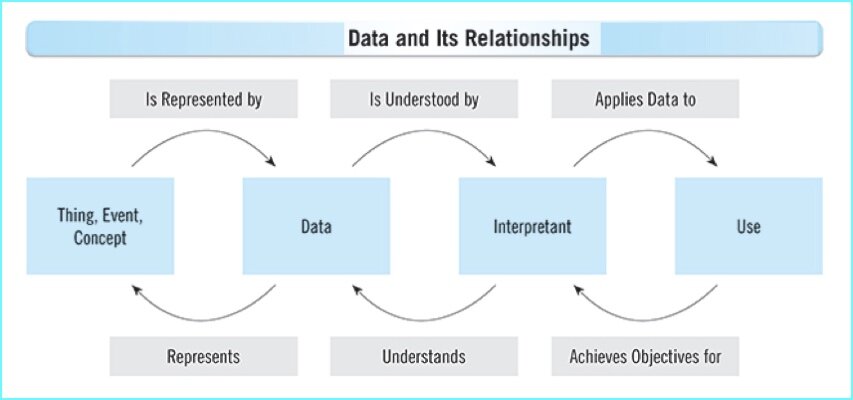
Spelling, pronunciation, and examples of usage are included in the dictionary definition of a word, which is a good example of one of the many uses of metadata, namely to provide a definition, description, and context for data.
Pictured to the left is the dictionary that has been on my desk for over 15 years, which is a good metaphor for the challenges of metadata management.
When I first bought the dictionary, it was, as its front cover attested, “The Newest. The Best. A Trusted Authority. A brand-new dictionary of the 1990s, for the 1990s. Comprehensive coverage of current words and terms, with clear, understandable definitions and up-to-the-minute usage guidance.”
And its back cover boasted of “60,000 entries assembled by a state-of-the-art authority using the most modern sources of information, and prepared by lexicographic experts to provide the one-stop reference book to turn to for all of your word questions.” (However, if one of your word questions was about metadata you were out of luck because it didn’t have an entry for it.)
The multidimensionality of metadata is exemplified by how a dictionary rarely contains a single definition for a word, and an old dictionary exemplifies how constantly changing semantics further complicate metadata management.
Using an old dictionary has several downsides, such as new words would not be in it, and some existing words would have either new definitions or an updated definition order based on the predominant context of current usage.
Organizations face a similar challenge while trying to maintain a metadata dictionary containing comprehensive coverage of business and technical terminology. Hopefully providing clear, understandable definitions and usage guidance prepared by subject matter experts, a metadata dictionary is a trusted authority and one-stop reference to turn to for all your data questions.
At least, that’s the theory. In practice, I haven’t encountered a metadata dictionary that could deliver on that promise.
And just as there are many dictionary publishers (e.g., Houghton Mifflin Harcourt, Merriam-Webster, Oxford University Press), as well as numerous online dictionaries (e.g., Collins, Urban, Wiktionary), there’s often more than one metadata dictionary within every organization as well. In fact, sometimes the organization has just as many metadata silos as it does data silos.
An old dictionary reminds us that language — and especially its everyday usage — evolves. An old dictionary also teaches us that metadata — and especially the data it defines, describes, and provides a context for — evolves as well. Which is probably why doing metadata management well is not, well, something that just automagically happens.