
Adventures in Data Profiling (Part 1)
/In my popular post Getting Your Data Freq On, I explained that understanding your data is essential to using it effectively and improving its quality – and to achieve these goals, there is simply no substitute for data analysis.
I explained the benefits of using a data profiling tool to help automate some of the grunt work, but that you need to perform the actual analysis and then prepare meaningful questions and reports to share with the rest of your team.
Series Overview
This post is the beginning of a vendor-neutral series on the methodology of data profiling.
In order to narrow the scope of the series, the scenario used will be that a customer data source for a new data quality initiative has been made available to an external consultant who has no prior knowledge of the data or its expected characteristics. Also, the business requirements have not yet been documented, and the subject matter experts are not currently available.
The series will not attempt to cover every possible feature of a data profiling tool or even every possible use of the features that are covered. Both the data profiling tool and the data used throughout the series will be fictional. The “screen shots” have been customized to illustrate concepts and are not modeled after any particular data profiling tool.
The Adventures Begin...
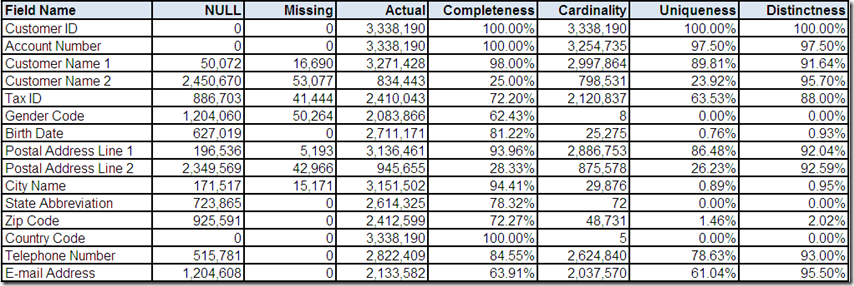
The customer data source has been processed by a data profiling tool, which has provided the above counts and percentages that summarize the following field content characteristics:
- NULL – count of the number of records with a NULL value
- Missing – count of the number of records with a missing value (i.e. non-NULL absence of data e.g. character spaces)
- Actual – count of the number of records with an actual value (i.e. non-NULL and non-missing)
- Completeness – percentage calculated as Actual divided by the total number of records
- Cardinality – count of the number of distinct actual values
- Uniqueness – percentage calculated as Cardinality divided by the total number of records
- Distinctness – percentage calculated as Cardinality divided by Actual
Some initial questions based on your analysis of these statistical summaries might include the following:
- Is Customer ID the primary key for this data source?
- Is Customer Name 1 the primary name on the account? If so, why isn't it always populated?
- Do the statistics for Account Number and/or Tax ID indicate the presence of potential duplicate records?
- Why does the Gender Code field have 8 distinct values?
- Do the 5 distinct values in Country Code indicate international postal addresses?
Please remember the series scenario – You are an external consultant with no prior knowledge of the data or its expected characteristics, who is performing this analysis without the aid of either business requirements or subject matter experts.
What other questions can you think of based on analyzing the statistical summaries provided by the data profiling tool?
In Part 2 of this series: We will continue the adventures by attempting to answer these questions (and more) by beginning our analysis of the frequency distributions of the unique values and formats found within the fields. Additionally, we will begin using drill-down analysis in order to perform a more detailed review of records of interest.
Related Posts
Adventures in Data Profiling (Part 2)
Adventures in Data Profiling (Part 3)
Adventures in Data Profiling (Part 4)
Adventures in Data Profiling (Part 5)
Adventures in Data Profiling (Part 6)
Adventures in Data Profiling (Part 7)

