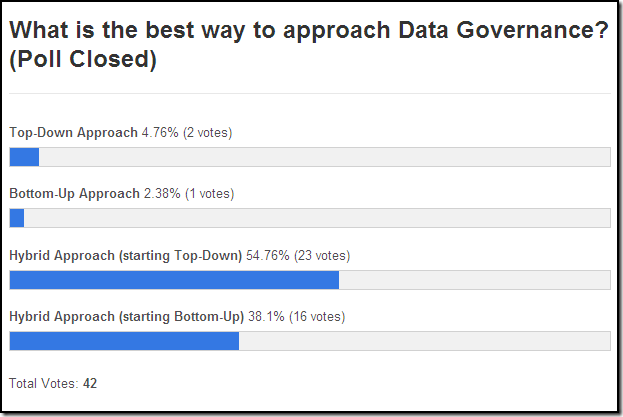
As I, and many others, have blogged about many times before, the proactive approach to data quality, i.e., defect prevention, is highly recommended over the reactive approach to data quality, i.e., data cleansing.
However, reactive data quality still remains the most common approach because “let’s wait and see if something bad happens” is typically much easier to sell strategically than “let’s try to predict the future by preventing something bad before it happens.”
Of course, when something bad does happen (and it always does), it is often too late to do anything about it. So imagine if we could somehow travel back in time and prevent specific business-impacting occurrences of poor data quality from happening.
This would appear to be the best of both worlds since we could reactively wait and see if something bad happens, and if (when) it does, then we could travel back in time and proactively prevent just that particular bad thing from happening to our data quality.
This approach is known as Retroactive Data Quality—and it has been (somewhat successfully) implemented at least three times.
Flux Capacitated Data Quality
 In 1985, Dr. Emmett “Doc” Brown turned a modified DeLorean DMC-12 into a retroactive data quality machine that when accelerated to 88 miles per hour, created a time displacement window using its flux capacitor (according to Doc it’s what makes time travel possible) powered by 1.21 gigawatts of electricity, which could be provided by either a nuclear reaction or a lightning strike.
In 1985, Dr. Emmett “Doc” Brown turned a modified DeLorean DMC-12 into a retroactive data quality machine that when accelerated to 88 miles per hour, created a time displacement window using its flux capacitor (according to Doc it’s what makes time travel possible) powered by 1.21 gigawatts of electricity, which could be provided by either a nuclear reaction or a lightning strike.
On October 25, 1985, Doc sent data quality expert Marty McFly back in time to November 5, 1955 to prevent a few data defects in the original design of the flux capacitor, which inadvertently triggers some severe data defects in 2015, requiring Doc and Marty to travel back to 1955, then 1885, before traveling Back to the Future of a defect-free 1985—when the flux capacitor is destroyed.
Quantum Data Quality

In 1989, theorizing a data steward could time travel within his own database, Dr. Sam Beckett launched a retroactive data quality project called Quantum Data Quality, stepped into its Quantum Leap data accelerator—and vanished.
He awoke to find himself trapped in the past, stewarding data that was not his own, and driven by an unknown force to change data quality for the better. His only guide on this journey was Al, a subject matter expert from his own time, who appeared in the form of a hologram only Sam could see and hear. And so, Dr. Beckett found himself leaping from database to database, putting data right that once went wrong, and hoping each time that his next leap would be the leap home to his own database—but Sam never returned home.
Data Quality Slingshot Effect
 The slingshot effect is caused by traveling in a starship at an extremely high warp factor toward a sun. After allowing the gravitational pull to accelerate it to even faster speeds, the starship will then break away from the sun, which creates the so-called slingshot effect that transports the starship through time.
The slingshot effect is caused by traveling in a starship at an extremely high warp factor toward a sun. After allowing the gravitational pull to accelerate it to even faster speeds, the starship will then break away from the sun, which creates the so-called slingshot effect that transports the starship through time.
In 2267, Captain Gene Roddenberry will begin a Star Trek, commanding a starship using the slingshot effect to travel back in time to September 8, 1966 to launch a retroactive data quality initiative that has the following charter:
“Data: the final frontier. These are the voyages of the starship Quality. Its continuing mission: To explore strange, new databases; To seek out new data and new corporations; To boldly go where no data quality has gone before.”
Retroactive Data Quality Log, Supplemental
It is understandable if many of you doubt the viability of time travel as an approach to improving your data quality. After all, whenever Doc and Marty, or Sam and Al, or Captain Roddenberry and the crew of the starship Quality, travel back in time and prevent specific business-impacting occurrences of poor data quality from happening, how do we prove they were successful? Within the resulting altered timeline, there would be no traces of the data quality issues after they were retroactively resolved.
“Great Scott!” It will always be more difficult to sell the business benefits of defect prevention, than the relative ease of selling data cleansing after a CxO responds “Oh, boy!” after the next time poor data quality negatively impacts business performance.
Nonetheless, you must continue your mission to engage your organization in a proactive approach to data quality. “Make It So!”
Related Posts
Groundhog Data Quality Day
What Data Quality Technology Wants
To Our Data Perfectionists
Finding Data Quality
MacGyver: Data Governance and Duct Tape
What going to the dentist taught me about data quality
Microwavable Data Quality
A Tale of Two Q’s
Hyperactive Data Quality (Second Edition)
The General Theory of Data Quality


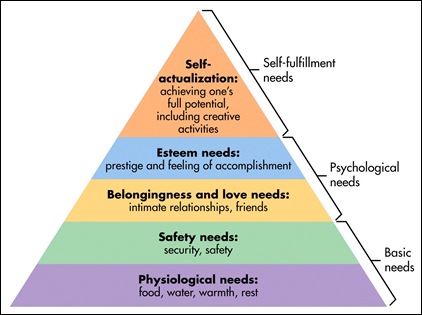 Abraham Maslow’s Hierarchy of Needs
Abraham Maslow’s Hierarchy of Needs Information Technology’s Hierarchy of Needs
Information Technology’s Hierarchy of Needs