Got Data Quality?
/
I have written many blog posts about how it’s neither a realistic nor a required data management goal to achieve data perfection, i.e., 100% data quality or zero defects.
Of course, this admonition logically invites the questions:
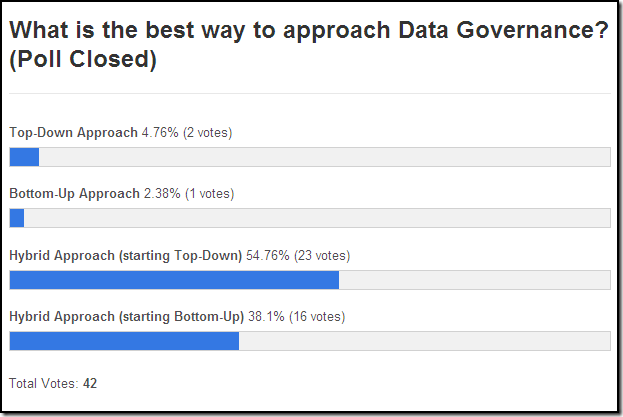
If achieving 100% data quality isn’t the goal, then what is?
99%?
98%?
As I was pondering these questions while grocery shopping, I walked down the dairy aisle casually perusing the wide variety of milk options, when the thought occurred to me that data quality issues have a lot in common with the fat content of milk.
The classification of the percentage of fat (more specifically butterfat) in milk varies slightly by country. In the United States, whole milk is approximately 3.25% fat, whereas reduced fat milk is 2% fat, low fat milk is 1% fat, and skim milk is 0.5% fat.
Reducing the total amount of fat (especially saturated and trans fat) is a common recommendation for a healthy diet. Likewise, reducing the total amount of defects (i.e., data quality issues) is a common recommendation for a healthy data management strategy. However, just like it would be unhealthy to remove all of the fat from your diet (because some fatty acids are essential nutrients that can’t be derived from other sources), it would be unhealthy to attempt to remove all of the defects from your data.
So maybe your organization is currently drinking whole data (i.e., 3.25% defects or 96.75% data quality) and needs to consider switching to reduced defect data (i.e., 2% defects or 98% data quality), low defect data (i.e., 1% defects or 99% data quality), or possibly even skim data (i.e., 0.5% defects or 99.5% data quality).

No matter what your perspective is regarding the appropriate data quality goal for your organization, at the very least, I think that we can all agree that all of our enterprise data management initiatives have to ask the question: “Got Quality?”
Related Posts
The Dichotomy Paradox, Data Quality and Zero Defects
The Real Data Value is Business Insight
Is your data complete and accurate, but useless to your business?
Thaler’s Apples and Data Quality Oranges
Data Quality and The Middle Way
The Data Quality Goldilocks Zone
You Can’t Always Get the Data You Want





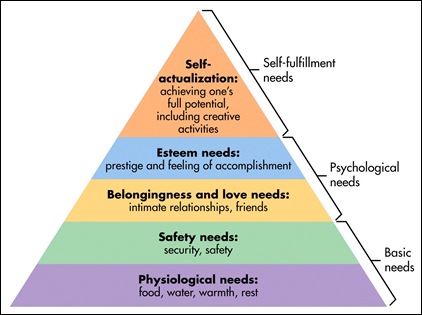 Abraham Maslow’s Hierarchy of Needs
Abraham Maslow’s Hierarchy of Needs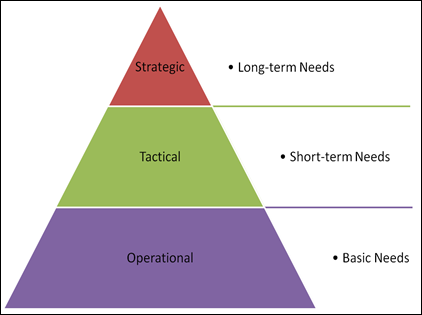 Information Technology’s Hierarchy of Needs
Information Technology’s Hierarchy of Needs