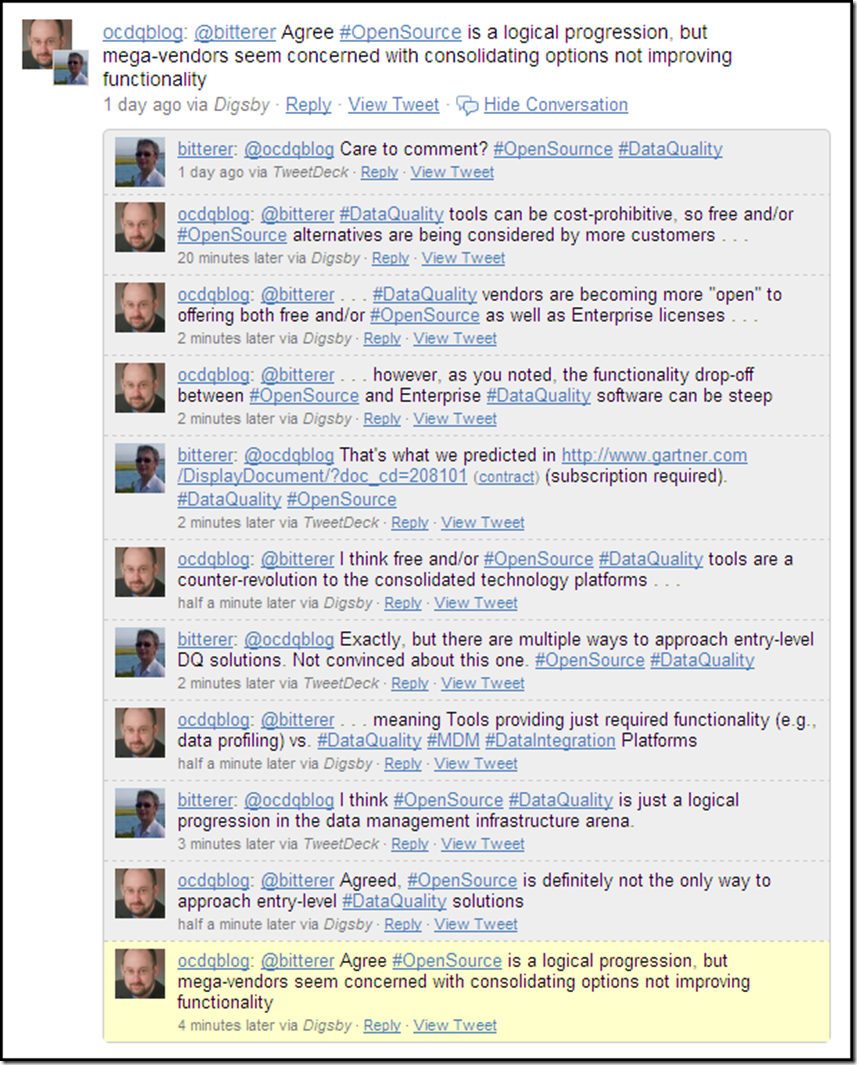
If you follow Data Quality on Twitter like I do, then you are probably already well aware that the 2010 Gartner Magic Quadrant for Data Quality Tools was released this week (surprisingly, it did not qualify as a Twitter trending topic).
The five vendors that were selected as the “data quality market leaders” were SAS DataFlux, IBM, Informatica, SAP Business Objects, and Trillium.
Disclosure: I am a former IBM employee, former IBM Information Champion, and I blog for the Data Roundtable, which is sponsored by SAS.
Please let me stress that I have the highest respect for both Ted Friedman and Andy Bitterer, as well as their in depth knowledge of the data quality industry and their insightful analysis of the market for data quality tools.
In this blog post, I simply want to encourage a good-natured debate, and not about the Gartner Magic Quadrant specifically, but rather about market research in general. Gartner is used as the example because they are perhaps the most well-known and the source most commonly cited by data quality vendors during the sales cycle—and obviously, especially by the “leading vendors.”
I would like to debate how much of an impact market research really has on a prospect’s decision to purchase a data quality tool.
Let’s agree to keep this to a very informal debate about how research can affect both the perception and the reality of the market.
Therefore—for the love of all high quality data everywhere—please, oh please, data quality vendors, do NOT send me your quarterly sales figures, or have your PR firm mercilessly spam either my comments section or my e-mail inbox with all the marketing collateral “proving” how Supercalifragilisticexpialidocious your data quality tool is—I said please, so play nice.
The OCDQ View on OOBE-DQ
In a previous post, I used the term OOBE-DQ to refer to the out-of-box-experience (OOBE) provided by data quality (DQ) tools, which usually becomes a debate between “ease of use” and “powerful functionality” after you ignore the Magic Beans sales pitch that guarantees you the data quality tool is both remarkably easy to use and incredibly powerful.
However, the data quality market continues to evolve away from esoteric technical tools and toward business-empowering suites providing robust functionality with easier to use and role-based interfaces that are tailored to the specific needs of different users, such as business analysts, data stewards, application developers, and system administrators.
The major players are still the large vendors who have innovated (mostly via acquisition and consolidation) enterprise application development platforms with integrated (to varying degrees) components, which provide not only data quality functionality, but also data integration and master data management (MDM) as well.
Many of these vendors also offer service-oriented deployments delivering the same functionality within more loosely coupled technical architectures, which includes leveraging real-time services to prevent (or at least greatly minimize) poor data quality at the multiple points of origin within the data ecosystem.
Many vendors are also beginning to provide better built-in reporting and data visualization capabilities, which is helping to make the correlation between poor data quality and suboptimal business processes more tangible, especially for executive management.
It must be noted that many vendors (including the “market leaders”) continue to struggle with their International OOBE-DQ.
Many (if not most) data quality tools are strongest in their native country or their native language, but their OOBE-DQ declines significantly when they travel abroad. Especially outside of the United States, smaller vendors with local linguistic and cultural expertise built into their data quality tools have continued to remain fiercely competitive with the larger vendors.
Market research certainly has a role to play in making a purchasing decision, and perhaps most notably as an aid in comparing and contrasting features and benefits, which of course, always have to be evaluated against your specific requirements, including both your current and future needs.
Now let’s shift our focus to examining some of the inherent challenges of evaluating market research, perception, and reality.
Confirmation Bias
First of all, I realize that this debate will suffer from a considerable—and completely understandable—confirmation bias.
If you are a customer, employee, or consultant for one of the “High Five” (not an “official” Gartner Magic Quadrant term for the Leaders), then obviously you have a vested interest in getting inebriated on your own Kool-Aid (as noted in my disclosure above, I used to get drunk on the yummy Big Blue Kool-Aid). Now, this doesn’t mean that you are a “yes man” (or a “yes woman”). It simply means it is logical for you to claim that market research, market perception, and market reality are in perfect alignment.
Likewise, if you are a customer, employee, or consultant for one of the “It Isn’t Easy Being Niche-y” (rather surprisingly, not an “official” Gartner Magic Quadrant term for the Niche Players), then obviously you have a somewhat vested interest in claiming that market research is from Mars, market perception is from Venus, and market reality is really no better than reality television.
And, if you are a customer, employee, or consultant for one of the “We are on the outside looking in, flipping both Gartner and their Magic Quadrant the bird for excluding us” (I think that you can figure out on your own whether or not that is an “official” Gartner Magic Quadrant term), then obviously you have a vested interest in saying that market research can “Kiss My ASCII!”
My only point is that your opinion of market research will obviously be influenced by what it says about your data quality tool.
Therefore, should it really surprise anyone when, during the sales cycle, one of the High Five uses the Truly Awesome Syllogism:
“Well, of course, we say our data quality tool is awesome.
However, the Gartner Magic Quadrant also says our data quality tool is awesome.
Therefore, our data quality tool is Truly Awesome.”
Okay, so technically, that’s not even a syllogism—but who said any form of logical argument is ever used during a sales cycle?
On a more serious note, and to stop having too much fun at Gartner’s expense, they do advise against simply selecting vendors in their “Leaders quadrant” and instead always advise to select the vendor that is the better match for your specific requirements.
Features and Benefits: The Game Nobody Wins
As noted earlier, a features and benefits comparison is not only the most common technique used by prospects, but it is also the most common—if not the only—way that the vendors themselves position their so-called “competitive differentiation.”
The problem with this approach—and not just for data quality tools—is that there are far more similarities than differences to be found when comparing features and benefits.
Practically every single data quality tool on the market today will include functionality for data profiling, data quality assessment, data standardization, data matching, data consolidation, data integration, data enrichment, and data quality monitoring.
Therefore, running down a checklist of features is like playing a game of Buzzword Bingo, or constantly playing Musical Chairs, but without removing any of the chairs in between rounds—in others words, the Features Game almost always ends in a tie.
So then next we play the Benefits Game, which is usually equally pointless because it comes down to silly arguments such as “our data matching engine is better than yours.” This is the data quality tool vendor equivalent of:
Vendor D: “My Dad can beat up your Dad!”
Vendor Q: “Nah-huh!”
Vendor D: “Yah-huh!”
Vendor Q: “NAH-HUH!”
Vendor D: “YAH-HUH!”
Vendor Q: “NAH-HUH!”
Vendor D: “Yah-huh! Stamp it! No Erasies! Quitsies!”
Vendor Q: “No fair! You can’t do that!”
After both vendors have returned from their “timeout,” a slightly more mature approach is to run a vendor “bake-off” where the dueling data quality tools participate in a head-to-head competition processing a copy of the same data provided by the prospect.
However, a bake-off often produces misleading results because the vendors—and not the prospect—perform the competition, making it mostly about vendor expertise, not OOBE-DQ. Also, the data used rarely exemplifies the prospect’s data challenges.
If competitive differentiation based on features and benefits is a game that nobody wins, then what is the alternative?
The Golden Circle

I recently read the book Start with Why by Simon Sinek, which explains that “people don’t buy WHAT you do, they buy WHY you do it.”
The illustration shows what Simon Sinek calls The Golden Circle.
WHY is your purpose—your driving motivation for action.
HOW is your principles—specific actions that are taken to realize your Why.
WHAT is your results—tangible ways in which you bring your Why to life.
It’s a circle when viewed from above, but in reality it forms a megaphone for broadcasting your message to the marketplace.
When you rely only on the approach of attempting to differentiate your data quality tool by discussing its features and benefits, you are focusing on only your WHAT, and absent your WHY and HOW, you sound just like everyone else to the marketplace.
When, as is often the case, nobody wins the Features and Benefits Game, a data quality tool sounds more like a commodity, which will focus the marketplace’s attention on aspects such as your price—and not on aspects such as your value.
Due to the considerable length of this blog post, I have been forced to greatly oversimplify the message of this book, which a future blog post will discuss in more detail. I highly recommend the book (and no, I am not an affiliate).
At the very least, consider this question:
If there truly was one data quality tool on the market today that, without question, had the very best features and benefits, then why wouldn’t everyone simply buy that one?
Of course your data quality tool has solid features and benefits—just like every other data quality tool does.
I believe that the hardest thing for our industry to accept is—the best technology hardly ever wins the sale.
As most of the best salespeople will tell you, what wins the sale is when a relationship is formed between vendor and customer, a strategic partnership built upon a solid foundation of rapport, respect, and trust.
And that has more to do with WHY you would make a great partner—and less to do with WHAT your data quality tool does.
Do you believe in Magic (Quadrants)?

How much of an impact do you think market research has on the purchasing decision of a data quality tool? How much do you think research affects both the perception and the reality of the data quality tool market? How much do you think the features and benefits of a data quality tool affect the purchasing decision?
All perspectives on this debate are welcome without bias. Therefore, please post a comment below.
PLEASE NOTE
Comments advertising your products and services (or bashing competitors) will not be approved.