
Commendable Comments (Part 13)
/Welcome to the 400th Obsessive-Compulsive Data Quality (OCDQ) blog post! I am commemorating this milestone with the 13th entry in my ongoing series for expressing gratitude to my readers for their truly commendable comments on my blog posts.
Commendable Comments
On Will Big Data be Blinded by Data Science?, Meta Brown commented:
“Your concern is well-founded. Knowing how few businesses make really good use of the small data they’ve had around all along, it’s easy to imagine that they won’t do any better with bigger data sets.
I wrote some hints for those wallowing into the big data mire in my post, Better than Brute Force: Big Data Analytics Tips. But the truth is that many organizations won’t take advantage of the ideas that you are presenting, or my tips, especially as the datasets grow larger. That’s partly because they have no history in scientific methods, and partly because the data science movement is driving employers to search for individuals with heroically large skill sets.
Since few, if any, people truly meet these expectations, those hired will have real human limitations, and most often they will be people who know much more about data storage and manipulation than data analysis and applications.”
On Will Big Data be Blinded by Data Science?, Mike Urbonas commented:
“The comparison between scientific inquiry and business decision making is a very interesting and important one. Successfully serving a customer and boosting competitiveness and revenue does require some (hopefully unique) insights into customer needs. Where do those insights come from?
Additionally, scientists also never stop questioning and improving upon fundamental truths, which I also interpret as not accepting conventional wisdom — obviously an important trait of business managers.
I recently read commentary that gave high praise to the manager utilizing the scientific method in his or her decision-making process. The author was not a technologist, but rather none other than Peter Drucker, in writings from decades ago.
I blogged about Drucker’s commentary, data science, the scientific method vs. business decision making, and I’d value your and others’ input: Business Managers Can Learn a Lot from Data Scientists.”
On Word of Mouth has become Word of Data, Vish Agashe commented:
“I would argue that listening to not only customers but also business partners is very important (and not only in retail but in any business). I always say that, even if as an organization you are not active in the social world, assume that your customers, suppliers, employees, competitors are active in the social world and they will talk about you (as a company), your people, products, etc.
So it is extremely important to tune in to those conversations and evaluate its impact on your business. A dear friend of mine ventured into the restaurant business a few years back. He experienced a little bit of a slowdown in his business after a great start. He started surveying his customers, brought in food critiques to evaluate if the food was a problem, but he could not figure out what was going on. I accidentally stumbled upon Yelp.com and noticed that his restaurant’s rating had dropped and there were some complaints recently about services and cleanliness (nothing major though).
This happened because he had turnover in his front desk staff. He was able to address those issues and was able to reach out to customers who had bad experience (some of them were frequent visitors). They were able to go back and comment and give newer ratings to his business. This helped him with turning the corner and helped with the situation.
This was a big learning moment for me about the power of social media and the need for monitoring it.”
On Data Quality and the Bystander Effect, Jill Wanless commented:
“Our organization is starting to develop data governance processes and one of the processes we have deliberately designed is to get to the root cause of data quality issues.
We’ve designed it so that the errors that are reported also include the userid and the system where the data was generated. Errors are then filtered by function and the business steward responsible for that function is the one who is responsible for determining and addressing the root cause (which of course may require escalation to solve).
The business steward for the functional area has the most at stake in the data and is typically the most knowledgeable as to the process or system that may be triggering the error. We have yet to test this as we are currently in the process of deploying a pilot stewardship program.
However, we are very confident that it will help us uncover many of the causes of the data quality problems and with lots of PLAN, DO, CHECK, and ACT, our goal is to continuously improve so that our need for stewardship eventually (many years away no doubt) is reduced.”
On The Return of the Dumb Terminal, Prashanta Chandramohan commented:
“I can’t even imagine what it’s like to use this iPad I own now if I am out of network for an hour. Supposedly the coolest thing to own and a breakthrough innovation of this decade as some put it, it’s nothing but a dumb terminal if I do not have 3G or Wi-Fi connectivity.
Putting most of my documents, notes, to-do’s, and bookmarked blogs for reading later (e.g., Instapaper) in the cloud, I am sure to avoid duplicating data and eliminate installing redundant applications.
(Oops! I mean the apps! :) )
With cloud-based MDM and Data Quality tools starting to linger, I can’t wait to explore and utilize the advantages these return of dumb terminals bring to our enterprise information management field.”
On Big Data Lessons from Orbitz, Dylan Jones commented:
“The fact is that companies have always done predictive marketing, they’re just getting smarter at it.
I remember living as a student in a fairly downtrodden area that because of post code analytics meant I was bombarded with letterbox mail advertising crisis loans to consolidate debts and so on. When I got my first job and moved to a new area all of a sudden I was getting loans to buy a bigger car. The companies were clearly analyzing my wealth based on post code lifestyle data.
Fast forward and companies can do way more as you say.
Teresa Cottam (Global Telecoms Analyst) has cited the big telcos as a major driver in all this, they now consider themselves data companies so will start to offer more services to vendors to track our engagement across the entire communications infrastructure (Read more here: http://bit.ly/xKkuX6).
I’ve just picked up a shiny new Mac this weekend after retiring my long suffering relationship with Windows so it will be interesting to see what ads I get served!”
And please check out all of the commendable comments received on the blog post: Data Quality and Chicken Little Syndrome.
Thank You for Your Comments and Your Readership
You are Awesome — which is why receiving your comments has been the most rewarding aspect of my blogging experience over the last 400 posts. Even if you have never posted a comment, you are still awesome — feel free to tell everyone I said so.
This entry in the series highlighted commendable comments on blog posts published between April 2012 and June 2012.
Since there have been so many commendable comments, please don’t be offended if one of your comments wasn’t featured.
Please continue commenting and stay tuned for future entries in the series.
Thank you for reading the Obsessive-Compulsive Data Quality blog. Your readership is deeply appreciated.
Related Posts
Commendable Comments (Part 12) – The Third Blogiversary of OCDQ Blog
Commendable Comments (Part 11)
Commendable Comments (Part 10) – The 300th OCDQ Blog Post
730 Days and 264 Blog Posts Later – The Second Blogiversary of OCDQ Blog
OCDQ Blog Bicentennial – The 200th OCDQ Blog Post
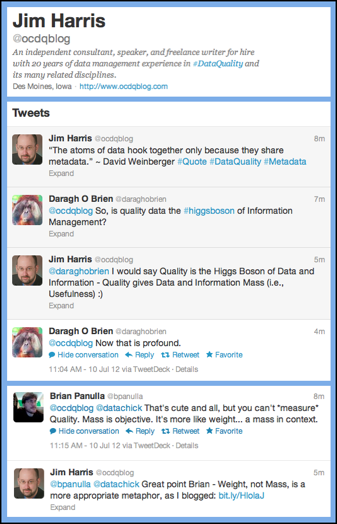 Recently on Twitter,
Recently on Twitter, 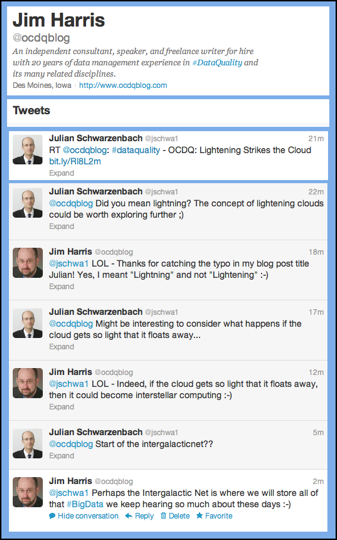 Last week, when I published my blog post
Last week, when I published my blog post 



