
Commendable Comments (Part 1)
/Six month ago today, I launched this blog by asking: Do you have obsessive-compulsive data quality (OCDQ)?
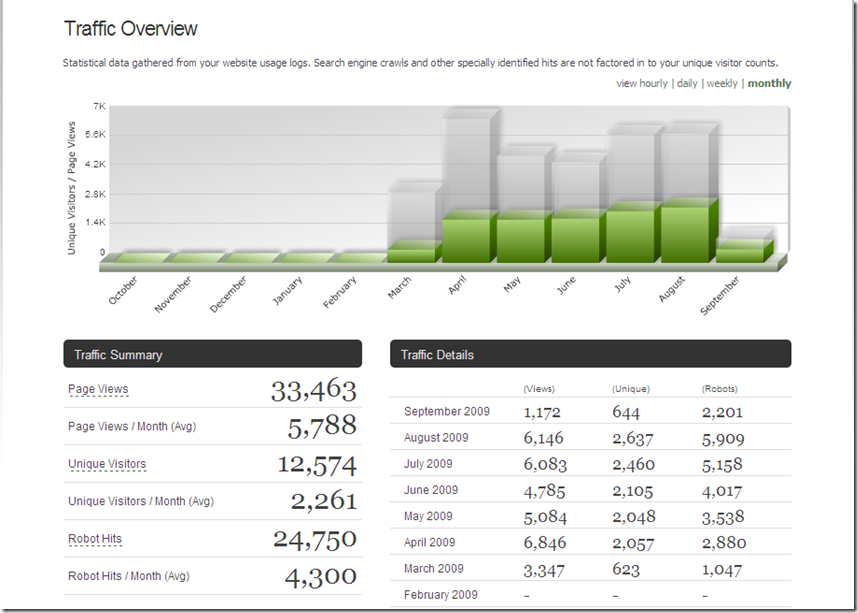
As of September 10, here are the monthly traffic statistics provided by my blog platform:
It Takes a Village (Idiot)
In my recent Data Quality Pro article Blogging about Data Quality, I explained why I started this blog. Blogging provides me a way to demonstrate my expertise. It is one thing for me to describe myself as an expert and another to back up that claim by allowing you to read my thoughts and decide for yourself.
In general, I have always enjoyed sharing my experiences and insights. A great aspect to doing this via a blog (as opposed to only via whitepapers and presentations) is the dialogue and discussion provided via comments from my readers.
This two-way conversation not only greatly improves the quality of the blog content, but much more importantly, it helps me better appreciate the difference between what I know and what I only think I know.
Even an expert's opinions are biased by the practical limits of their personal experience. Having spent most of my career working with what is now mostly IBM technology, I sometimes have to pause and consider if some of that yummy Big Blue Kool-Aid is still swirling around in my head (since I “think with my gut,” I have to “drink with my head”).
Don't get me wrong – “You're my boy, Blue!” – but there are many other vendors and all of them also offer viable solutions driven by impressive technologies and proven methodologies.
Data quality isn't exactly the most exciting subject for a blog. Data quality is not just a niche – if technology blogging was a Matryoshka (a.k.a. Russian nested) doll, then data quality would be the last, innermost doll.
This doesn't mean that data quality isn't an important subject – it just means that you will not see a blog post about data quality hitting the front page of Digg anytime soon.
All blogging is more art than science. My personal blogging style can perhaps best be described as mullet blogging – not “business in the front, party in the back” but “take your subject seriously, but still have a sense of humor about it.”
My blog uses a lot of metaphors and analogies (and sometimes just plain silliness) to try to make an important (but dull) subject more interesting. Sometimes it works and sometimes it sucks. However, I have never been afraid to look like an idiot. After all, idiots are important members of society – they make everyone else look smart by comparison.
Therefore, I view my blog as a Data Quality Village. And as the Blogger-in-Chief, I am the Village Idiot.
The Rich Stuff of Comments
Earlier this year in an excellent IT Business Edge article by Ann All, David Churbuck of Lenovo explained:
“You can host focus groups at great expense, you can run online surveys, you can do a lot of polling, but you won’t get the kind of rich stuff (you will get from blog comments).”
How very true. But before we get to the rich stuff of our village, let's first take a look at a few more numbers:
- Not counting this one, I have published 44 posts on this blog
- Those blog posts have collectively received a total of 185 comments
- Only 5 blog posts received no comments
- 30 comments were actually me responding to my readers
- 45 comments were from LinkedIn groups (23), SmartData Collective re-posts (17), or Twitter re-tweets (5)
The ten blog posts receiving the most comments:
- The Two Headed Monster of Data Matching – 11 Comments
- Adventures in Data Profiling (Part 4) – 9 Comments
- Adventures in Data Profiling (Part 2) – 9 Comments
- You're So Vain, You Probably Think Data Quality Is About You – 8 Comments
- There are no Magic Beans for Data Quality – 8 Comments
- The General Theory of Data Quality – 8 Comments
- Adventures in Data Profiling (Part 1) – 8 Comments
- To Parse or Not To Parse – 7 Comments
- The Wisdom of Failure – 7 Comments
- The Nine Circles of Data Quality Hell – 7 Comments
Commendable Comments
This post will be the first in an ongoing series celebrating my heroes – my readers.
As Darren Rowse and Chris Garrett explained in their highly recommended ProBlogger book: “even the most popular blogs tend to attract only about a 1 percent commenting rate.”
Therefore, I am completely in awe of my blog's current 88 percent commenting rate. Sure, I get my fair share of the simple and straightforward comments like “Great post!” or “You're an idiot!” – but I decided to start this series because I am consistently amazed by the truly commendable comments that I regularly receive.
On The Data Quality Goldilocks Zone, Daragh O Brien commented:
“To take (or stretch) your analogy a little further, it is also important to remember that quality is ultimately defined by the consumers of the information. For example, if you were working on a customer data set (or 'porridge' in Goldilocks terms) you might get it to a point where Marketing thinks it is 'just right' but your Compliance and Risk management people might think it is too hot and your Field Sales people might think it is too cold. Declaring 'Mission Accomplished' when you have addressed the needs of just one stakeholder in the information can often be premature.
Also, one of the key learnings that we've captured in the IAIDQ over the past 5 years from meeting with practitioners and hosting our webinars is that, just like any Change Management effort, information quality change requires you to break the challenge into smaller deliverables so that you get regular delivery of 'just right' porridge to the various stakeholders rather than boiling the whole thing up together and leaving everyone with a bad taste in their mouths. It also means you can more quickly see when you've reached the Goldilocks zone.”
On Data Quality Whitepapers are Worthless, Henrik Liliendahl Sørensen commented:
“Bashing in blogging must be carefully balanced.
As we all tend to find many things from gurus to tools in our own country, I have also found one of my favourite sayings from Søren Kirkegaard:
If One Is Truly to Succeed in Leading a Person to a Specific Place, One Must First and Foremost Take Care to Find Him Where He is and Begin There.
This is the secret in the entire art of helping.
Anyone who cannot do this is himself under a delusion if he thinks he is able to help someone else. In order truly to help someone else, I must understand more than he–but certainly first and foremost understand what he understands.
If I do not do that, then my greater understanding does not help him at all. If I nevertheless want to assert my greater understanding, then it is because I am vain or proud, then basically instead of benefiting him I really want to be admired by him.
But all true helping begins with a humbling.
The helper must first humble himself under the person he wants to help and thereby understand that to help is not to dominate but to serve, that to help is not to be the most dominating but the most patient, that to help is a willingness for the time being to put up with being in the wrong and not understanding what the other understands.”
On All I Really Need To Know About Data Quality I Learned In Kindergarten, Daniel Gent commented:
“In kindergarten we played 'Simon Says...'
I compare it as a way of following the requirements or business rules.
Simon says raise your hands.
Simon says touch your nose.
Touch your feet.
With that final statement you learned very quickly in kindergarten that you can be out of the game if you are not paying attention to what is being said.
Just like in data quality, to have good accurate data and to keep the business functioning properly you need to pay attention to what is being said, what the business rules are.
So when Simon says touch your nose, don't be touching your toes, and you'll stay in the game.”
Since there have been so many commendable comments, I could only list a few of them in the series debut. Therefore, please don't be offended if your commendable comment didn't get featured in this post. Please keep on commenting and stay tuned for future entries in the series.
Because of You
As Brian Clark of Copyblogger explains, The Two Most Important Words in Blogging are “You” and “Because.”
I wholeheartedly agree, but prefer to paraphrase it as: Blogging is “because of you.”
Not you meaning me, the blogger – you meaning you, the reader.
Thank You.
Related Posts



