
Best OCDQ Blog Posts of 2013
/A roundup of the Best OCDQ Blog posts published during 2013.
Read MoreA roundup of the Best OCDQ Blog posts published during 2013.
Read MoreDuring this OCDQ Radio episode, guest Clarence Hempfield discusses aspects of spatial data quality and the business applications of spatial data for enterprise location intelligence.
Read MorePondering why superhero stories seem eerily similar to data quality and if poor quality is data’s antihero — a central character lacking some of the conventional heroic attributes but nonetheless benefits the greater good.
Read MorePondering whether the blemishing effect could positively affect your efforts to make the business case for a data quality initiative.
Read MoreData Quality By Example (DQ-BE) is an OCDQ regular segment that provides examples of data quality key concepts.
 Over the weekend, in preparation for watching the Boston Red Sox, I bought some beer and pizza. Later that night, after a thrilling victory that sent the Red Sox to the 2013 World Series, I was cleaning up the kitchen and was about to throw out the receipt when I couldn’t help but notice two data quality issues.
Over the weekend, in preparation for watching the Boston Red Sox, I bought some beer and pizza. Later that night, after a thrilling victory that sent the Red Sox to the 2013 World Series, I was cleaning up the kitchen and was about to throw out the receipt when I couldn’t help but notice two data quality issues.
First, although I had purchased Samuel Adams Octoberfest, the receipt indicated I had bought Spring Ale, which, although it’s still available in some places and it’s still good beer, it’s three seasonal beers (Summer Ale, Winter Lager, Octoberfest) old. This data quality issue impacts the store’s inventory and procurement systems (e.g., maybe the store orders more Spring Ale next year because people were apparently still buying it in October this year).
The second, and far more personal, data quality issue was that the age verification portion of my receipt indicated I was born on or before November 22, 1922, making me at least 91 years old! While I am of the age (42) typical of a midlife crisis, I wasn’t driving a new red sports car, just wearing my old Red Sox sports jersey and hat. As for the store, this data quality issue could be viewed as a regulatory compliance failure since it seems like their systems are set up by default to allow the sale of alcohol without proper age verification. Additionally, this data quality issue might make it seem like their only alcohol-purchasing customers are very senior citizens.
What examples (good or poor) of data quality have you encountered? Please share them by posting a comment below.
|
DQ-BE: The Time Traveling Gift Card DQ-BE: Invitation to Duplication |
Sometimes Worse Data Quality is Better |
Inspired by the great Eagles song Hotel California, this DQ-Song “sings” about the common mistake of convening a council too early when starting a new data governance program. Now, of course, data governance is a very important and serious subject, which is why some people might question whether or not music is the best way to discuss data governance.
Although I understand that skepticism, I can’t help but recall the words of Frank Zappa:
“Information is not knowledge;
Knowledge is not wisdom;
Wisdom is not truth;
Truth is not beauty;
Beauty is not love;
Love is not music;
Music is the best.”
Down a dark deserted hallway, I walked with despair
As the warm smell of bagels rose up through the air
Up ahead in the distance, I saw a shimmering light
My head grew heavy and my sight grew dim
I had to attend another data governance council meeting
As I stood in the doorway
I heard the clang of the meeting bell
And I was thinking to myself
This couldn’t be heaven, but this could be hell
As stakeholders argued about the data governance way
There were voices down the corridor
I thought I heard them say . . .
Welcome to the Council Data Governance
Such a dreadful place (such a dreadful place)
Time crawls along at such a dreadful pace
Plenty of arguing at the Council Data Governance
Any time of year (any time of year)
You can hear stakeholders arguing there
Their agendas are totally twisted, with means to their own end
They use lots of pretty, pretty words, which I don’t comprehend
How they dance around the complex issues with sweet sounding threats
Some speak softly with remorse, some speak loudly without regrets
So I cried out to the stakeholders
Can we please reach consensus on the need for collaboration?
They said, we haven’t had that spirit here since nineteen ninety nine
And still those voices they’re calling from far away
Wake you up in the middle of this endless meeting
Just to hear them say . . .
Welcome to the Council Data Governance
Such a dreadful place (such a dreadful place)
Time crawls along at such a dreadful pace
They argue about everything at the Council Data Governance
And it’s no surprise (it’s no surprise)
To hear defending the status quo alibis
Bars on all of the windows
Rambling arguments, anything but concise
We are all just prisoners here
Of our own device
In the data governance council chambers
The bickering will never cease
They stab it with their steely knives
But they just can’t kill the beast
Last thing I remember, I was
Running for the door
I had to find the passage back
To the place I was before
Relax, said the stakeholders
We have been programmed by bureaucracy to believe
You can leave the council meeting any time you like
But success with data governance, you will never achieve!
OCDQ Radio is an audio podcast about data quality and its related disciplines, produced and hosted by Jim Harris.
During this episode, I am joined by special guest Dr. Alexander Borek, the inventor of Total Information Risk Management (TIRM) and the leading expert on how to apply risk management principles to data management. Dr. Borek is a frequent speaker at international information management conferences and author of many research articles covering a range of topics, including EIM, data quality, crowd sourcing, and IT business value. In his current role at IBM, Dr. Borek applies data analytics to drive IBM’s worldwide corporate strategy. Previously, he led a team at the University of Cambridge to develop the TIRM process and test it in a number of different industries. He holds a PhD in engineering from the University of Cambridge.
This podcast discusses his book Total Information Risk Management: Maximizing the Value of Data and Information Assets, which is now available world-wide and is a must read for all data and information managers who want to understand and measure the implications of low quality data and information assets. The book provides step by step instructions, along with illustrative examples from studies in many different industries, on how to implement total information risk management, which will help your organization:
Learn how to manage data and information for business value.
Create powerful and convincing business cases for all your data and information management, data governance, big data, data warehousing, business intelligence, and business analytics initiatives, projects, and programs.
Protect your organization from risks that arise through poor data and information assets.
Quantify the impact of having poor data and information.
Clicking on the link will take you to the episode’s blog post:

Convincing your organization to invest in a sustained data quality program implemented within a data governance framework can be a very difficult task requiring an advocate with a championship pedigree. But sometimes it seems like no matter how persuasive your sales pitch is, even when your presentation is judged best in show, it appears to fall on deaf ears.
Perhaps, data governance (DG) is a D-O-G. In other words, maybe the DG message is similar to a sound only dogs can hear.
In the late 19th century, Francis Galton developed a whistle (now more commonly called a dog whistle), which he used to test the range of frequencies that could be heard by various animals. Galton was conducting experiments on human faculties, including the range of human hearing. Although not its intended purpose, today Galton’s whistle is used by dog trainers. By varying the frequency of the whistle, it emits a sound (inaudible to humans) used either to simply get a dog’s attention, or alternatively to inflict pain for the purpose of correcting undesirable behavior.
Many organizations do not become aware of the importance of data governance until poor data quality repeatedly “bites” critical business decisions. Typically following a very nasty bite, executives scream “bad data, bad, bad data!” without stopping to realize the enterprise’s poor data management practices unleashed the perpetually bad data now running amuck within their systems.
For these organizations, advocacy of proactive defect prevention was an inaudible sound, and now the executives blow harshly into their data whistle and demand a one-time data cleansing project to correct the current data quality problems.
However, even after the project is over, it’s often still a doggone crazy data world.
Executing disconnected one-off projects to deal with data issues when they become too big to ignore doesn’t work because it doesn’t identify and correct the root causes of data’s bad behavior. By advocating root cause analysis and business process improvement, data governance can essentially be understood as The Data Whisperer.
Data governance defines policies and procedures for aligning data usage with business metrics, establishes data stewardship, prioritizes data quality issues, and facilitates collaboration among all of the business and technical stakeholders.
Data governance enables enterprise-wide data quality by combining data cleansing (which will still occasionally be necessary) and defect prevention into a hybrid discipline, which will result in you hearing everyday tales about data so well behaved that even your executives’ tails will be wagging.
Without question, data governance is very disruptive to an organization’s status quo. It requires patience, understanding, and dedication because it will require a strategic enterprise-wide transformation that doesn’t happen overnight.
However, data governance is also data’s best friend.
And in order for your organization to be successful, you have to realize that data is also your best friend. Data governance will help you take good care of your data, which in turn will take good care of your business.
Basically, the success of your organization comes down to a very simple question — Are you a DG person?
OCDQ Radio is an audio podcast about data quality and its related disciplines, produced and hosted by Jim Harris.
During this episode, Adam Cox and I discuss data quality project management, avoiding data quality becoming an afterthought on data integration and data migration projects, the difference and relationship between data ownership and data stewardship, regulatory requirements for data quality, and the importance of getting buy-in from business stakeholders.
Adam Cox is a data management professional with over ten years of experience working in the public and private sector in the United Kingdom (UK). He is an experienced project and technical manager working on large-scale projects involving significant data migration and data integration. Adam Cox is currently working for an established UK financial institution as a Data Quality Consultant, mainly on regulatory reporting projects.
Clicking on the link will take you to the episode’s blog post:

“As a single stone causes concentric ripples in a pond,” Martin Doyle commented on my blog post There is No Such Thing as a Root Cause, “there will always be one root cause event creating the data quality wave. There may be interference after the root cause event which may look like a root cause, creating eddies of side effects and confusion, but I believe there will always be one root cause. Work backwards from the data quality side effects to the root cause and the data quality ripples will be eliminated.”
Martin Doyle and I continued our congenial blog comment banter on my podcast episode The Johari Window of Data Quality, but in this blog post I wanted to focus on the stone-throwing metaphor for root cause analysis.
Let’s begin with the concept of a single stone causing the concentric ripples in a pond. Is the stone really the root cause? Who threw the stone? Why did that particular person choose to throw that specific stone? How did the stone come to be alongside the pond? Which path did the stone-thrower take to get to the pond? What happened to the stone-thrower earlier in the day that made them want to go to the pond, and once there, pick up a stone and throw it in the pond?
My point is that while root cause analysis is important to data quality improvement, too often we can get carried away riding the ripples of what we believe to be the root cause of poor data quality. Adding to the complexity is the fact there’s hardly ever just one stone. Many stones get thrown into our data ponds, and trying to un-ripple their poor quality effects can lead us to false conclusions because causation is non-linear in nature. Causation is a complex network of many interrelated causes and effects, so some of what appear to be the effects of the root cause you have isolated may, in fact, be the effects of other causes.
As Laura Sebastian-Coleman explains, data quality assessments are often “a quest to find a single criminal—The Root Cause—rather than to understand the process that creates the data and the factors that contribute to data issues and discrepancies.” Those approaching data quality this way, “start hunting for the one thing that will explain all the problems. Their goal is to slay the root cause and live happily ever after. Their intentions are good. And slaying root causes—such as poor process design—can bring about improvement. But many data problems are symptoms of a lack of knowledge about the data and the processes that create it. You cannot slay a lack of knowledge. The only way to solve a knowledge problem is to build knowledge of the data.”
Believing that you have found and eliminated the root cause of all your data quality problems is like believing that after you have removed the stones from your pond (i.e., data cleansing), you can stop the stone-throwers by building a high stone-deflecting wall around your pond (i.e., defect prevention). However, there will always be stones (i.e., data quality issues) and there will always be stone-throwers (i.e., people and processes) that will find a way to throw a stone in your pond.
In our recent podcast Measuring Data Quality for Ongoing Improvement, Laura Sebastian-Coleman and I discussed although root cause is used as a singular noun, just as data is used as a singular noun, we should talk about root causes since, just as data analysis is not analysis of a single datum, root cause analysis should not be viewed as analysis of a single root cause.
The bottom line, or, if you prefer, the ripple at the bottom of the pond, is the Stone Wars of Root Cause Analysis will never end because data quality is a journey, not a destination. After all, that’s why it’s called ongoing data quality improvement.
OCDQ Radio is an audio podcast about data quality and its related disciplines, produced and hosted by Jim Harris.
Listen to Laura Sebastian-Coleman, author of the book Measuring Data Quality for Ongoing Improvement: A Data Quality Assessment Framework, and I discuss bringing together a better understanding of what is represented in data, and how it is represented, with the expectations for use in order to improve the overall quality of data. Our discussion also includes avoiding two common mistakes made when starting a data quality project, and defining five dimensions of data quality.
Laura Sebastian-Coleman has worked on data quality in large health care data warehouses since 2003. She has implemented data quality metrics and reporting, launched and facilitated a data quality community, contributed to data consumer training programs, and has led efforts to establish data standards and to manage metadata. In 2009, she led a group of analysts in developing the original Data Quality Assessment Framework (DQAF), which is the basis for her book.
Laura Sebastian-Coleman has delivered papers at MIT’s Information Quality Conferences and at conferences sponsored by the International Association for Information and Data Quality (IAIDQ) and the Data Governance Organization (DGO). She holds IQCP (Information Quality Certified Professional) designation from IAIDQ, a Certificate in Information Quality from MIT, a B.A. in English and History from Franklin & Marshall College, and a Ph.D. in English Literature from the University of Rochester.
Clicking on the link will take you to the episode’s blog post:
A Data Quality (DQ) View is a brief video discussion of a data quality key concept.
If you are having trouble viewing this video, then you can watch it on Vimeo by clicking on this link: DQ-View on Vimeo
Keep Looking Up Insights in Data
DQ-View: The Five Stages of Data Quality
DQ-View: MetaData makes BettahMusic
DQ-View: Baseball and Data Quality
DQ-View: Roman Ruts on the Road to Data Governance
Data Quality is not a Magic Trick
How Data Cleansing Saves Lives
DQ-View: The Poor Data Quality Blizzard
DQ-View: From Data to Decision
DQ View: Achieving Data Quality Happiness
DQ-View: Is Data Quality the Sun?
DQ-View: Designated Asker of Stupid Questions

The title of my recent blog post Chaos in the Big Data Brickyard made Mike Wheeler think it was a reference to the Indianapolis Motor Speedway, which is known as “The Brickyard” because it was paved entirely with bricks way back in 1909 (today, three feet of the original bricks remain at the start/finish line). This was a reasonable assumption by Wheeler since he is a NASCAR fan (thus making his last name a great example of an aptronym) and thus prompted his blog post Yeah, But Who Won The Race?
“The term brickyard taken without any context,” Wheeler explained, “turned out to be another random brick of fact laid on an already crowded foundation. Context is what provides relevance to facts. Without a frame of reference into which a fact can be inserted it can easily become meaningless or, even worse, detrimental to the decision-making process.”
As usual, I agree with Wheeler (except about being a NASCAR fan — my apologies to Mike and his fellow auto racing fans).
In my post Big Data, Sporks, and Decision Frames, I blogged about how having the right decision frame (i.e., understanding the business context of a decision) is essential to whether big data and data science can provide meaningful business insight.
Additional context often missing from discussions about big data and data science is that they are not the only bricks in the yard.
Data modeling is still important and data quality still matters. As does metadata, data management and business intelligence, data monitoring, communication, collaboration, change management and the many other aspects of data governance.
“A successful man,” David Brinkley once said, “is one who can lay a firm foundation with the bricks others have thrown at him.” A successful big data initiative is one that can lay a firm foundation with the bricks of best practices that the data management industry has been rightfully throwing at us for a long time now. Big data does not obviate the need for those best practices — even though it does occasionally require adapting our best practices as well as adopting new practices.
Big data is not the be all and end all, as it is sometimes overhyped, but instead, to paraphrase the great philosophers Pink Floyd:
All in all, big data is just another brick in the wall.
Clicking on the link will take you to the episode’s blog post:
Data Quality By Example (DQ-BE) is an OCDQ regular segment that provides examples of data quality key concepts.
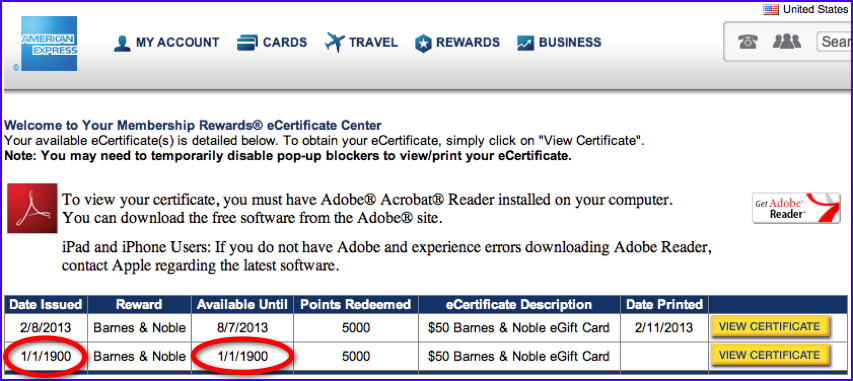
As an avid reader, I tend to redeem most of my American Express Membership Rewards points for Barnes & Noble gift cards to buy new books for my Nook. As a data quality expert, I tend to notice when something is amiss with data. As shown above, for example, my recent gift card was apparently issued on — and only available for use until — January 1, 1900.
At first, I thought I might have encountered the time traveling gift card. However, I doubted the gift card would be accepted as legal tender in 1900. Then I thought my gift card was actually worth $1,410 (what $50 in 1900 would be worth today), which would allow me to buy a lot more books — as long as Barnes & Noble would overlook the fact the gift card expired 113 years ago.
Fortunately, I was able to use the gift card to purchase $50 worth of books in 2013.
So, I guess the moral of this story is that sometimes poor data quality does pay. However, it probably never pays to display your poor data quality to someone who runs an obsessive-compulsive data quality blog with a series about data quality by example.
What examples (good or poor) of data quality have you encountered in your time travels?
|
DQ-BE: Invitation to Duplication |
In my post The Wisdom of Crowds, Friends, and Experts, I used Amazon, Facebook, and Pandora respectively as examples of three techniques used by the recommendation engines increasingly provided by websites, social networks, and mobile apps.
Richard Jarvis commented that my assessment of the data quality associated with these techniques actually needed to look at metadata, data, and information, as well as knowledge management. “For crowd-sourced data, we’re assessing quality based on the first-order value rather than the immediate downstream usability. We’re not questioning the accuracy of Amazon’s assertion that customers who purchased X also purchased Y. Rather, we’re interested in the relevance of that information. In terms of knowledge management, I would describe this as broadening data quality to embrace information and knowledge quality.”
As usual, I agreed with Richard. Amazon is not providing access to the operational data underlying their recommendations, which is, of course, understandable, but instead Amazon is providing some aggregated information (e.g., sales rank) along with some detailed information (e.g., consumer reviews) and numerous metadata attributes (e.g., product category).
We have no way of knowing if the underlying operational data is accurate (as well as other aspects of data quality), nor do we have any way of verifying any aspect of the information quality. Some of the metadata could be verified by cross-referencing other sources (e.g., for books, we could verify the metadata with the publishers and other sellers such as Barnes & Noble).
Making use of Amazon’s information has to be done on the assumption of quality — something that data and information quality professionals would never endorse in other contexts (e.g., within Amazon’s internal financial accounting systems).
While this situation has always existed, the Internet and the era of big data is exacerbating it. Although this example focused on recommendation engines, many of the sources involved in big data analytics face this same challenge, such as sentiment analysis and other analysis that is dependent upon self-reported data.
Furthermore, I would argue that many, for lack of a better term, traditional data and information management applications, have functioned off of the same assumption of quality even though data and information quality best practices are implemented.
By extension, although there is an assumption that quality business decisions can only be made based on quality metadata, data, and information, if that were true in all cases, then every business would be bankrupt.
None of this is meant to imply that quality is not important.
On the contrary, my point is that in almost every application of metadata, data, and information, there is an assumption of quality. Obviously, this assumption should be tested whenever it can be, but we have to accept the fact that there will be many times when we will not be able to, thus forcing us to leverage metadata, data, and information on the assumption of their quality.
Obsessive-Compulsive Data Quality (OCDQ) is a blog offering a vendor-neutral perspective on data quality and its related disciplines.
| Home | Blog | Podcast | Videos | Best of OCDQ | Published Articles | About | Contact |
|
© 2022, Jim Harris. |
Powered by Squarespace |

