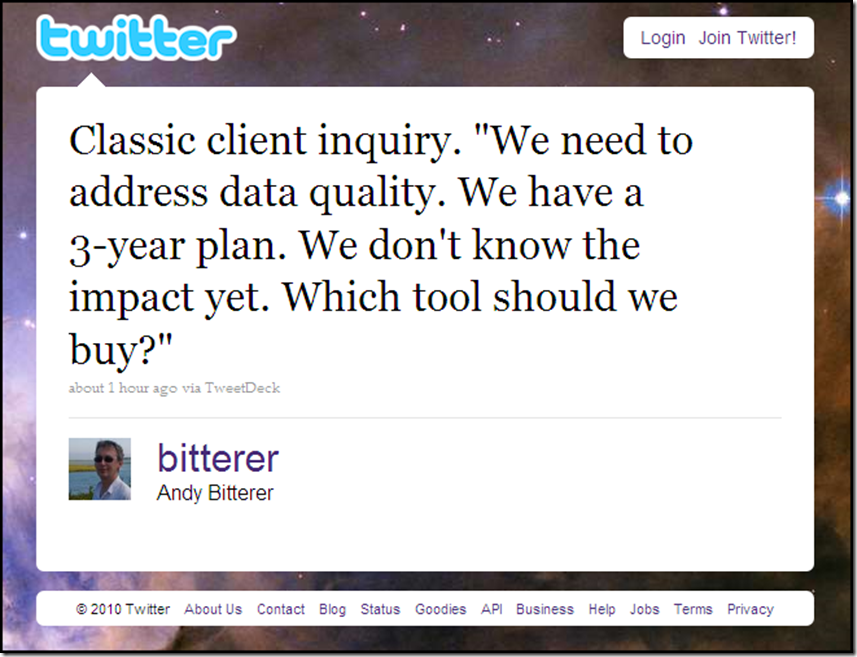
This recent tweet by Andy Bitterer of Gartner Research (and ANALYSTerical) sparked an interesting online discussion, which was vaguely reminiscent of the classic causality dilemma that is commonly stated as “which came first, the chicken or the egg?”
An E-mail from the Edge
On the same day I saw Andy’s tweet, I received an e-mail from a friend and fellow data quality consultant, who had just finished a master data management (MDM) and enterprise data warehouse (EDW) project, which had over 20 customer data sources.
Although he was brought onto the project specifically for data cleansing, he was told from the day of his arrival that because of time constraints, they decided against performing any data cleansing with their recently purchased data quality tool. Instead, they decided to use their data integration tool to simply perform the massive initial load into their new MDM hub and EDW.
But wait—the story gets even better. The very first decision this client made was to purchase a consolidated enterprise application development platform with seamlessly integrated components for data quality, data integration, and master data management.
So long before this client had determined their business need, they decided that they needed to build a new MDM hub and EDW, made a huge investment in an entire platform of technology, then decided to use only the basic data integration functionality.
However, this client was planning to use the real-time data quality and MDM services provided by their very powerful enterprise application development platform to prevent duplicates and any other bad data from entering the system after the initial load.
But, of course, no one on the project team was actually working on configuring any of those services, or even, for that matter, determining the business rules those services would enforce. Maybe the salesperson told them it was as easy as flipping a switch?
My friend (especially after looking at the data), preached data quality was a critical business need, but he couldn’t convince them, even despite taking the initiative to present the results of some quick data profiling, standardization, and data matching used to identify duplicate records within and across their primary data sources, which clearly demonstrated the level of poor data quality.
Although this client agreed that they definitely had some serious data issues, they still decided against doing any data cleansing and wanted to just get the data loaded. Maybe they thought they were loading the data into one of those self-healing databases?
The punchline—this client is a financial services institution with a business need to better identify their most valuable customers.
As my friend lamented at the end of his e-mail, why do clients often later ask why these types of projects fail?
Blind Vendor Allegiance
In his recent blog post Blind Vendor Allegiance Trumps Utility, Evan Levy examined this bizarrely common phenomenon of selecting a technology vendor without gathering requirements, reviewing product features, and then determining what tool(s) could best help build solutions for specific business problems—another example of the tool coming before the business need.
Evan was recounting his experiences at a major industry conference on MDM, where people were asking his advice on what MDM vendor to choose, despite admitting “we know we need MDM, but our company hasn’t really decided what MDM is.”
Furthermore, these prospective clients had decided to default their purchasing decision to the technology vendor they already do business with, in other words, “since we’re already a [you can just randomly insert the name of a large technology vendor here] shop, we just thought we’d buy their product—so what do you think of their product?”
“I find this type of question interesting and puzzling,” wrote Evan. “Why would anyone blindly purchase a product because of the vendor, rather than focusing on needs, priorities, and cost metrics? Unless a decision has absolutely no risk or cost, I’m not clear how identifying a vendor before identifying the requirements could possibly have a successful outcome.”
SaaS-y Data Quality on a Cloudy Business Day?
Emerging industry trends like open source, cloud computing, and software as a service (SaaS) are often touted as less expensive than traditional technology, and I have heard some use this angle to justify buying the tool before identifying the business need.
In his recent blog post Cloud Application versus On Premise, Myths and Realities, Michael Fauscette examined the return on investment (ROI) versus total cost of ownership (TCO) argument quite prevalent in the SaaS versus on premise software debate.
“Buying and implementing software to generate some necessary business value is a business decision, not a technology decision,” Michael concluded. “The type of technology needed to meet the business requirements comes after defining the business needs. Each delivery model has advantages and disadvantages financially, technically, and in the context of your business.”
So which came first, the Data Quality Tool or the Business Need?
This question is, of course, absurd because, in every rational theory, the business need should always come first. However, in predictably irrational real-world practice, it remains a classic causality dilemma for data quality related enterprise information initiatives such as data integration, master data management, data warehousing, business intelligence, and data governance.
But sometimes the data quality tool was purchased for an earlier project, and despite what some vendor salespeople may tell you, you don’t always need to buy new technology at the beginning of every new enterprise information initiative.
Whenever, and before defining your business need, you already have the technology in-house (or you have previously decided, often due to financial constraints, that you will need to build a bespoke solution), you still need to avoid technology bias.
Knowing how the technology works can sometimes cause a framing effect where your business need is defined in terms of the technology’s specific functionality, thereby framing the objective as a technical problem instead of a business problem.
Bottom line—your business problem should always be well-defined before any potential technology solution is evaluated.
Related Posts
There are no Magic Beans for Data Quality
Do you believe in Magic (Quadrants)?
Is your data complete and accurate, but useless to your business?
Can Enterprise-Class Solutions Ever Deliver ROI?
Selling the Business Benefits of Data Quality
The Circle of Quality

 Understanding your
Understanding your 
 I grew up and lived most of my life in the suburbs of Boston, Massachusetts. But just prior to relocating to the Midwest for work seven years ago, I lived in Derry, New Hampshire, just down the road from the
I grew up and lived most of my life in the suburbs of Boston, Massachusetts. But just prior to relocating to the Midwest for work seven years ago, I lived in Derry, New Hampshire, just down the road from the