From Vality Technology, through Ascential Software, and eventually with IBM, I have spent most of my career working with the data quality tool that is now known as IBM InfoSphere QualityStage.
Throughout my time in Research and Development (as a Senior Software Engineer and a Development Engineer) and Professional Services (as a Principal Consultant and a Senior Technical Instructor), I was often asked to wear many hats for QualityStage – and not just because my balding head is distractingly shiny.
True champions are championship teams. The QualityStage team (past and present) is the most remarkable group of individuals that I have ever had the great privilege to know, let alone the good fortune to work with. Thank you all very, very much.
The IBM Information Champion Program
Previously known as the Data Champion Program, the IBM Information Champion Program honors individuals making outstanding contributions to the Information Management community.
Technical communities, websites, books, conference speakers, and blogs all contribute to the success of IBM’s Information Management products. But these activities don’t run themselves.
Behind the scenes, there are dedicated and loyal individuals who put in their own time to run user groups, manage community websites, speak at conferences, post to forums, and write blogs. Their time is uncompensated by IBM.
IBM honors the commitment of these individuals with a special designation — Information Champion — as a way of showing their appreciation for the time and energy these exceptional community members expend.
Information Champions are objective experts. They have no official obligation to IBM.
They simply share their opinions and years of experience with others in the field, and their work contributes greatly to the overall success of IBM Information Management.
We are the Champions
The IBM Information Champion Program has been expanded from the Data Management segment to all segments in Information Management, and now includes IBM Cognos, Enterprise Content Management, and InfoSphere.
Today is Friday, which for Twitter users like me, can mean only one thing...
Every Friday, Twitter users recommend other users that you should follow. FollowFriday has kind of become the Twitter version of peer pressure – in other words, I recommended you, why didn't you recommend me?
Among my fellow Twitter addicts, it has come to be viewed either as a beloved tradition of social media community building, or a hated annoyance. It is almost as deeply polarizing as Pepsi vs. Coke or Soccer vs. Football (by the way, just for the official record, I love FollowFriday and I am firmly in the Pepsi and Football camps – and by Football, I mean American Football).
In this blog post, I want to provide you with some examples of what I do on FollowFriday, and how I manage to actually follow (or do I?) so many people (586 and counting).
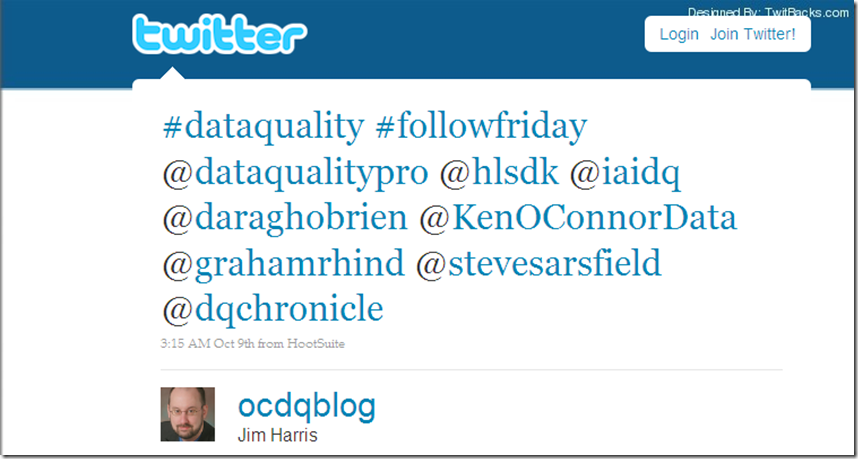
FollowFriday Example # 1 – The List
Perhaps the most common example of a FollowFriday tweet is to simply list as many users as you can within the 140 characters:
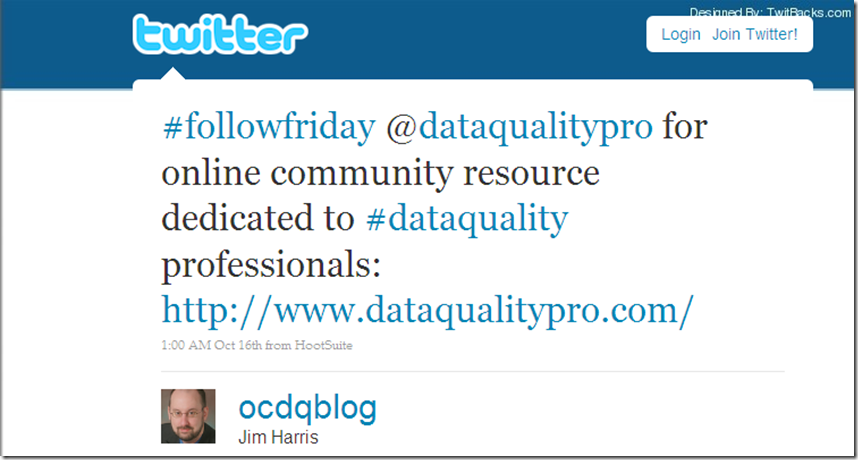
FollowFriday Example # 2 – The Tweet-Out
An alternative FollowFriday tweet is to send a detailed Tweet-Out (the Twitter version of a Shout-Out) to a single user:
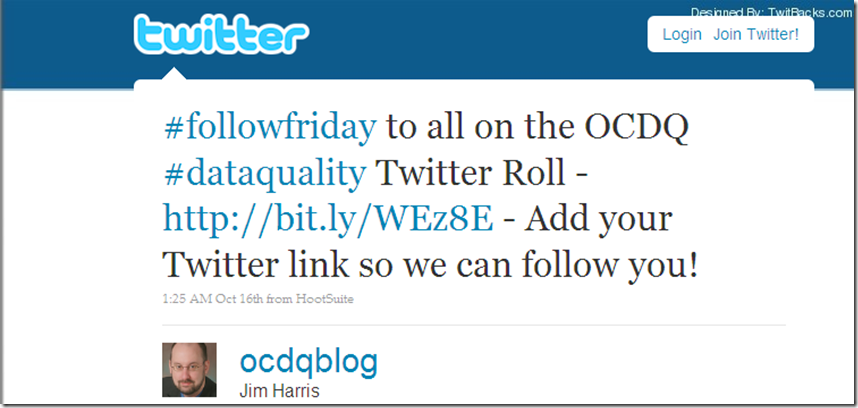
FollowFriday Example # 3 – The Twitter Roll
Yet another alternative FollowFriday tweet is to send a link to a Twitter Roll (the Twitter version of a Blog Roll):
To add your Twitter link so we can follow you, please click here: OCDQ Twitter Roll
Give a Hoot, Use HootSuite
Most of my FollowFriday tweets are actually scheduled. In part, I do this because I follow people from all around the world and by the time I finally crawl out of bed on Friday, many of my tweeps have already started their weekend. And let's face it, the other reason that I schedule my FollowFriday tweets has a lot to do with why obsessive-compulsive is in the name of my blog.
Please note that the limitation of 140 characters has necessitated the abbreviation #FF instead of the #followfriday “standard.”
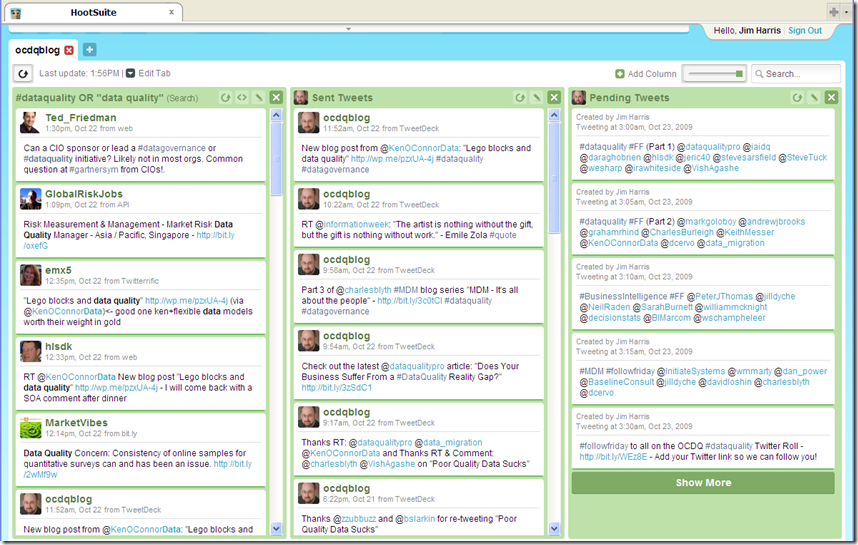
The Tweet-rix
Unless you only follow a few people, it is a tremendous challenge to actually follow every user you follow. To be perfectly honest, I do not follow everyone I follow – no, I wasn't just channeling Yogi Berra (I am a Boston Red Sox fan!). To borrow an analogy from Phil Simon, trying to watch your entire Twitter stream (i.e. The Tweet-rix) is like being an operator on The Matrix.
Not that I am all about me, but I do pay the most attention to Mentions and Direct Messages. Next, since I am primarily interested in data quality, I use an embedded search to follow any tweets that use the #dataquality hashtag or mention the phrase “data quality.” TweetDeck is one of many clients allowing you to create Groups of users to help organize The Tweet-rix.
To further prove my Sci-Fi geek status, I created a group called TweetDeck Actual, which is an homage to BattleStar Galactica, where saying “This is Galactica Actual” confirms an open communications channel has been established with the Galactica.
I rotate the users I follow in and out of TweetDeck Actual on a regular basis in order to provide for a narrowly focused variety of trenchant tweets. (By the way, I learned the word trenchant from a Jill Dyché tweet).
The Search for Tweets
You do not need to actually have a Twitter account in order to follow tweets. There are several search engines designed specifically for Twitter. And according to recent rumors, tweets will be coming soon to a Google near you.
Here are a just a few ways to search Twitter for data quality content:
With apologies to fellow fans of U2 (one of my all-time favorite bands):
If you tweet away, tweet away I tweet away, tweet away I will follow If you tweet away, tweet away I tweet away, tweet away I will follow I will follow
For those readers who are not baseball fans, the Los Angeles Angels of Anaheim swept the Red Sox out of the playoffs. I will let Miller's words describe their demise: “Down two to none in the best of five series, the Red Sox took a 6-4 lead into the ninth inning, turning control over to impenetrable closer Jonathan Papelbon, who hadn't allowed a run in 26 postseason innings. The Angels, within one strike of defeat on three occasions, somehow managed a miracle rally, scoring 3 runs to take the lead 7-6, then holding off the Red Sox in the bottom of the ninth for the victory to complete the shocking sweep.”
Baseball and Data Quality
What, you may be asking, does baseball have to do with data quality? Beyond simply being two of my all-time favorite topics, quite a lot actually. Baseball data is mostly transaction data describing the statistical events of games played.
Statistical analysis has been a beloved pastime even longer than baseball has been America's Pastime. Number-crunching is far more than just a quantitative exercise in counting. The qualitative component of statistics – discerning what the numbers mean, analyzing them to discover predictive patterns and trends – is the very basis of data-driven decision making.
“The Red Sox,” as Miller explained, “are certainly exemplars of the data and analytic team-building methodology” chronicled in Moneyball: The Art of Winning an Unfair Game, the 2003 book by Michael Lewis. Red Sox General Manager Theo Epstein has always been an advocate of the so-called evidenced-based baseball, or baseball analytics, pioneered by Bill James, the baseball writer, historian, statistician, current Red Sox consultant, and founder of Sabermetrics.
In another book that Miller and I both highly recommend, Super Crunchers, author Ian Ayres explained that “Bill James challenged the notion that baseball experts could judge talent simply by watching a player. James's simple but powerful thesis was that data-based analysis in baseball was superior to observational expertise. James's number-crunching approach was particular anathema to scouts.”
“James was baseball's herald,” continues Ayres, “of data-driven decision making.”
The Drunkard's Walk
As Mlodinow explains in the prologue: “The title The Drunkard's Walk comes from a mathematical term describing random motion, such as the paths molecules follow as they fly through space, incessantly bumping, and being bumped by, their sister molecules. The surprise is that the tools used to understand the drunkard's walk can also be employed to help understand the events of everyday life.”
Later in the book, Mlodinow describes the hidden effects of randomness by discussing how to build a mathematical model for the probability that a baseball player will hit a home run: “The result of any particular at bat depends on the player's ability, of course. But it also depends on the interplay of many other factors: his health, the wind, the sun or the stadium lights, the quality of the pitches he receives, the game situation, whether he correctly guesses how the pitcher will throw, whether his hand-eye coordination works just perfectly as he takes his swing, whether that brunette he met at the bar kept him up too late, or the chili-cheese dog with garlic fries he had for breakfast soured his stomach.”
“If not for all the unpredictable factors,” continues Mlodinow, “a player would either hit a home run on every at bat or fail to do so. Instead, for each at bat all you can say is that he has a certain probability of hitting a home run and a certain probability of failing to hit one. Over the hundreds of at bats he has each year, those random factors usually average out and result in some typical home run production that increases as the player becomes more skillful and then eventually decreases owing to the same process that etches wrinkles in his handsome face. But sometimes the random factors don't average out. How often does that happen, and how large is the aberration?”
Conclusion
I have heard some (not Mlodinow or anyone else mentioned in this post) argue that data quality is an irrelevant issue. The basis of their argument is that poor quality data are simply random factors that, in any data set of statistically significant size, will usually average out and therefore have a negligible effect on any data-based decisions.
However, the random factors don't always average out. It is important to not only measure exactly how often poor quality data occur, but acknowledge the large aberration poor quality data are, especially in data-driven decision making.
As every citizen of Red Sox Nation is taught from birth, the only acceptable opinion of our American League East Division rivals, the New York Yankees, is encapsulated in the chant heard throughout the baseball season (and not just at Fenway Park):
“Yankees Suck!”
From their inception, the day-to-day business decisions of every organization are based on its data. This decision-critical information drives the operational, tactical, and strategic initiatives essential to the enterprise's mission to survive and thrive in today's highly competitive and rapidly evolving marketplace.
It doesn't quite roll off the tongue as easily, but a chant heard throughout these enterprise information initiatives is:
In Part 6 of this series: You completed your initial analysis of the Account Number and Tax ID fields.
Previously during your adventures in data profiling, you have looked at customer name within the context of other fields. In Part 2, you looked at the associated customer names during drill-down analysis on the Gender Code field while attempting to verify abbreviations as well as assess NULL and numeric values. In Part 6, you investigated customer names during drill-down analysis for the Account Number and Tax ID fields while assessing the possibility of duplicate records.
In Part 7 of this award-eligible series, you will complete your initial analysis of this data source with direct investigation of the Customer Name 1 and Customer Name 2 fields.
Previously, the data profiling tool provided you with the following statistical summaries for customer names:
As we discussed when we looked at the E-mail Addressfield(in Part 3) and the Postal Address Line fields(in Part 5), most data profiling tools will provide the capability to analyze fields using formats that are constructed by parsing and classifying the individual values within the field.
Customer Name 1 and Customer Name 2 are additional examples of the necessity of this analysis technique. Not only are the cardinality of these fields very high, but they also have a very high Distinctness (i.e. the exact same field value rarely occurs on more than one record).
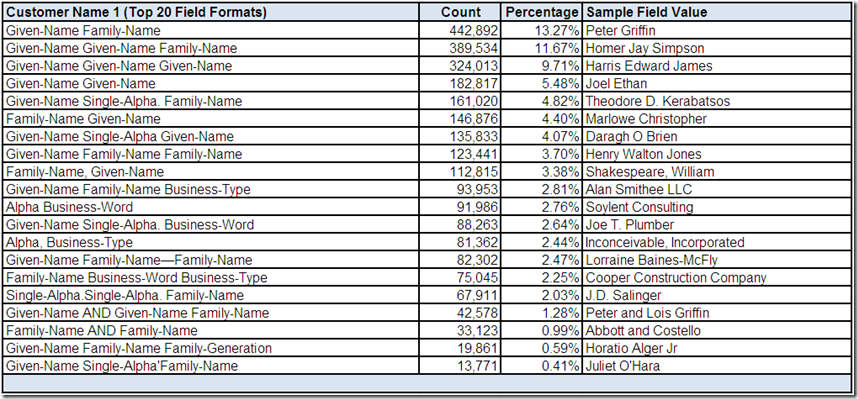
Customer Name 1
The data profiling tool has provided you the following drill-down “screen” for Customer Name 1:
Please Note: The differentiation between given and family names has been based on our fictional data profiling tool using probability-driven non-contextual classification of the individual field values.
For example, Harris, Edward, and James are three of the most common names in the English language, and although they can also be family names, they are more frequently given names. Therefore, “Harris Edward James” is assigned “Given-Name Given-Name Given-Name” for a field format. For this particular example, how do we determine the family name?
The top twenty most frequently occurring field formats for Customer Name 1 collectively account for over 80% of the records with an actual value in this field for this data source. All of these field formats appear to be common potentially valid structures. Obviously, more than one sample field value would need to be reviewed using more drill-down analysis.
What conclusions, assumptions, and questions do you have about the Customer Name 1 field?
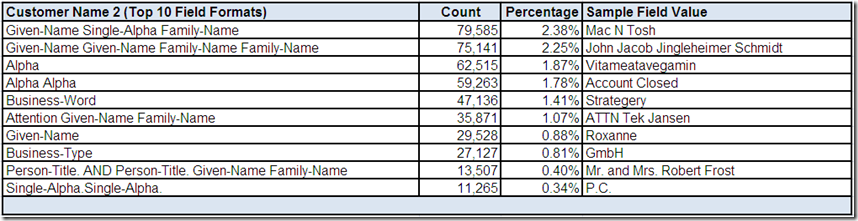
Customer Name 2
The data profiling tool has provided you the following drill-down “screen” for Customer Name 2:
The top ten most frequently occurring field formats for Customer Name 2 collectively account for over 50% of the records with an actual value in this sparsely populated field for this data source. Some of these field formats show common potentially valid structures. Again, more than one sample field value would need to be reviewed using more drill-down analysis.
What conclusions, assumptions, and questions do you have about the Customer Name 2 field?
The Challenges of Person Names
Not that business names don't have their own challenges, but person names present special challenges. Many data quality initiatives include the business requirement to parse, identify, verify, and format a “valid” person name. However, unlike postal addresses where country-specific postal databases exist to support validation, no such “standards” exist for person names.
In his excellent book Viral Data in SOA: An Enterprise Pandemic, Neal A. Fishman explains that “a person's name is a concept that is both ubiquitous and subject to regional variations. For example, the cultural aspects of an individual's name can vary. In lieu of last name, some cultures specify a clan name. Others specify a paternal name followed by a maternal name, or a maternal name followed by a paternal name; other cultures use a tribal name, and so on. Variances can be numerous.”
“In addition,” continues Fishman, “a name can be used in multiple contexts, which might affect what parts should or could be communicated. An organization reporting an employee's tax contributions might report the name by using the family name and just the first letter (or initial) of the first name (in that sequence). The same organization mailing a solicitation might choose to use just a title and a family name.”
However, it is not a simple task to identify what part of a person's name is the family name or the first given name (as some of the above data profiling sample field values illustrate). Again, regional, cultural, and linguistic variations can greatly complicate what at first may appear to be a straightforward business request (e.g. formatting a person name for a mailing label).
As Fishman cautions, “many regions have cultural name profiles bearing distinguishing features for words, sequences, word frequencies, abbreviations, titles, prefixes, suffixes, spelling variants, gender associations, and indications of life events.”
If you know of any useful resources for dealing with the challenges of person names, then please share them by posting a comment below. Additionally, please share your thoughts and experiences regarding the challenges (as well as useful resources) associated with business names.
What other analysis do you think should be performed for customer names?
In Part 8 of this series: We will conclude the adventures in data profiling with a summary of the lessons learned.
“Comment sections are communities strengthened by people.”
“Building a blog community creates a festival of people” where everyone can, as Chartrand explained, “speak up with great care and attention, sharing thoughts and views while openly accepting differing opinions.”
I agree with James (and not just because of his cool first name) – my goal for this blog is to foster an environment in which a diversity of viewpoints is freely shared without bias. Everyone is invited to get involved in the discussion and have an opportunity to hear what others have to offer. This blog's comment section has become a community strengthened by your contributions.
This is the third entry in my ongoing series celebrating my heroes – my readers.
“In my field of Software Development, you simply cannot rest and rely on what you know. The technology you master today will almost certainly evolve over time and this can catch you out. There's no point being an expert in something no one wants any more! This is not always the case, but don't forget to come up for air and look around for what's changing.
I've lost count of the number of organizations I've seen who have stuck with a technology that was fresh 15 years ago and a huge stagnant pot of data, who are now scrambling to come up to speed with what their customers expect. Throwing endless piles of cash at the problem, hoping to catch up.
What am I getting at? The secret I've learned is to adapt. This doesn't mean jump on every new fad immediately, but be aware of it. Follow what's trending, where the collective thinking is heading and most importantly, what do your customers want?
I just wish more organizations would think like this and realize that the systems they create, the data they hold, and the customers they have are in a constant state of flux. They are all projects that need care and attention. All subject to change, there's no getting away from it, but small, well planned changes are a lot less painful, trust me.”
“I have to agree with Rick about data quality being in the eye of the beholder – and with Henrik on the several dimensions of quality.
A theme I often return to is 'what does the business want/expect from data?' – and when you hear them talk about quality, it's not just an issue of accuracy. The business stakeholder cares – more than many seem to notice – about a number of other issues that are squarely BI concerns:
– Timeliness ('WHEN I want it') – Format ('how I want to SEE it') – visualization, delivery channels – Usability ('how I want to then make USE of it') – being able to extract information from a report (say) for other purposes – Relevance ('I want HIGHLIGHTED the information that is meaningful to me')
And so on. Yes, accuracy is important, and it messes up your effectiveness when delivering inaccurate information. But that's not the only thing a business stakeholder can raise when discussing issues of quality. A report can be rejected as poor quality if it doesn't adequately meet business needs in a far more general sense. That is the constant challenge for a BI professional.”
'Tell me and I'll forget; Show me and I may remember; Involve me and I'll understand.'
I have found the above to be very true, especially when seeking to brief a large team on a new policy or process. Interaction with the audience generates involvement and a better understanding.
The challenge facing books, whitepapers, blog posts etc. is that they usually 'Tell us,' they often 'Show us,' but they seldom 'Involve us.'
Hence, we struggle to remember, and struggle even more to understand. We learn best by 'doing' and by making mistakes.”
You Are Awesome
Thank you very much for your comments. For me, the best part of blogging is the dialogue and discussion provided by interactions with my readers. Since there have been so many commendable comments, please don't be offended if your commendable comment hasn't been featured yet. Please keep on commenting and stay tuned for future entries in the series.
By the way, even if you have never posted a comment on my blog, you are still awesome — feel free to tell everyone I said so.
As I blogged about in Data Gazers (borrowing that excellent phrase from Arkady Maydanchik), within cubicles randomly dispersed throughout the sprawling office space of companies large and small, there exist countless unsung heroes of data quality initiatives. Although their job titles might be labeling them as a Business Analyst, Programmer Analyst, Account Specialist or Application Developer, their true vocation is a far more noble calling. They are Data Gazers.
A most bizarre phenomenon (that I have witnessed too many times) is that as a data quality initiative “progresses” it tends to get further and further away from the people who use the data on a daily basis.
Please follow the excellent advice of Gian and Arkady — go talk with your users.
Trust me — everyone on your data quality initiative will be very happy that you did.
A “blog-bout” is a good-natured debate between two bloggers. This blog-bout is between Jim Harris and Phil Simon, where they debate which board game is the better metaphor for an Information Technology (IT) project: “Risk” or “Monopoly.”
IT projects and “Risk” have a great deal in common. I thought long and hard about this while screaming obscenities and watching professional sports on television, the source of all of my great thinking. I came up with five world dominating reasons.
1. Both things start with the players marking their territory. In Risk, the game begins with the players placing their “armies” on the territories they will initially occupy. On IT projects, the different groups within the organization will initially claim their turf.
Please note that the term “Information Technology” is being used in a general sense to describe a project (e.g. Data Quality, Master Data Management, etc.) and should not be confused with the IT group within an organization. At a very high level, the Business and IT are the internal groups representing the business and technical stakeholders on a project.
The Business usually owns the data and understands its meaning and use in the day-to-day operation of the enterprise. IT usually owns the hardware and software infrastructure of the enterprise's technical architecture.
Both groups can claim they are only responsible for what they own, resist collaborating with the “other side” and therefore create organizational barriers as fiercely defended as the continental borders of Europe and Asia in Risk.
2. In both, there are many competing strategies. In Risk, the official rules of the game include some basic strategies and over the years many players have developed their own fool-proof plans to guarantee victory. Some strategies advocate focusing on controlling entire continents, while others advise fortifying your borders by invading and occupying neighboring territories. And my blog-bout competitor Phil Simon half-jokingly claims that the key to winning Risk is securing the island nation of Madagascar.
On IT projects, you often hear a lot of buzzwords and strategies bandied about, such as Lean, Agile, Six Sigma, and Kaizen, to name but a few. Please understand – I am an advocate for methodology and best practices, and there are certainly many excellent frameworks out there, including the paradigms I just mentioned.
However, a general problem that I have with most frameworks is their tendency to adopt a one-size-fits-all strategy, which I believe is an approach that is doomed to fail. Any implemented framework must be customized to adapt to an organization’s unique culture.
In part, this is necessary because implementing changes of any kind will be met with initial resistance, but an attempt at forcing a one-size-fits-all approach almost sends a message to the organization that everything they are currently doing is wrong, which will of course only increase the resistance to change.
Starting with a framework simply provides a reference of best practices and recommended options of what has worked on successful IT projects. The framework should be reviewed in order to determine what can be learned from it and to select what will work in the current environment and what simply won't.
3. Pyrrhic victories are common during both endeavors. In Risk, sacrificing everything to win a single battle or to defend your favorite territory can ultimately lead you to lose the war. Political fiefdoms can undermine what could otherwise have been a successful IT project. Do not underestimate the unique challenges of your corporate culture.
Obviously, business, technical and data issues will all come up from time to time, and there will likely be disagreements regarding how these issues should be prioritized. Some issues will likely affect certain stakeholders more than others.
Keeping data and technology aligned with business processes requires getting people aligned and free to communicate their concerns. Coordinating discussions with all of the stakeholders and maintaining open communication can prevent a Pyrrhic victory for one stakeholder causing the overall project to fail.
4. Alliances are the key to true victory. In Risk, it is common for players to form alliances by combining their resources and coordinating their efforts in order to defend their shared borders or to eliminate a common enemy.
On IT projects, knowledge about data, business processes and supporting technology are spread throughout the organization. Neither the Business nor IT alone has all of the necessary information required to achieve success.
Successful projects are driven by an executive management mandate for the Business and IT to forge an alliance of ongoing and iterative collaboration throughout the entire project.
5. The outcomes of both are too often left to chance. IT projects are complex, time-consuming, and expensive enterprise initiatives. Success requires people taking on the challenge united by collaboration, guided by an effective methodology, and implementing a solution using powerful technology.
But the complexity of an IT project can sometimes work against your best intentions. It is easy to get pulled into the mechanics of documenting the business requirements and functional specifications, drafting the project plan and then charging ahead on the common mantra: “We planned the work, now we work the plan.”
Once an IT project achieves some momentum, it can take on a life of its own and the focus becomes more and more about making progress against the tasks in the project plan, and less and less on the project's actual business goals. Typically, this leads to another all too common mantra: “Code it, test it, implement it into production, and then declare victory.”
In Risk, the outcomes are literally determined by a roll of the dice. If you allow your IT project to lose sight of its business goals, then you treat it like a game of chance. And to paraphrase Albert Einstein:
“Do not play dice with IT Projects.”
Why “Monopoly” is a better metaphor for an IT Project
IT projects and “Monopoly” have a great deal in common. I thought long and hard about this at the gym, the source of all of my great thinking. I came up with six really smashing reasons.
1. Both things take much longer than originally expected. IT projects typically take much longer than expected for a wide variety of reasons. Rare is the project that finishes on time (with expected functionality delivered).
The same holds true for Monopoly. Remember when you were a kid and you wanted to play a quick game? Now, I consider the term “a quick game of Monopoly” to be the very definition of an oxymoron. You’d better block off about four to six hours for a proper game. Unforeseen complexities will doubtlessly delay even the best intentions.
2. During both endeavors, screaming matches typically erupt. Many projects become tense. I remember one in which two participants nearly came to blows. Most projects have key players engage in very heated debates over strategic vision and execution.
With Monopoly, especially after the properties are divvied up, players scream and yell over what constitutes a “fair” deal. “What do you mean Boardwalk for Ventnor Avenue and Pennsylvania Railroad isn’t reasonable? IT’S COMPLETELY FAIR!” Debates like this are the rule, not the exception.
3. While the basic rules may be the same, different people play by different rules. The vast majority of projects on which I have worked have had the usual suspects: steering committees, executive sponsors, PMOs, different stages of testing, and ultimately system activation. However, different organizations often try to do things in vastly different ways. For example, on two similar projects in different organizations, you are likely to find differences with respect to:
the number of internal and external folks assigned to a project
the project’s timeline and budget
project objectives
By the same token, people play Monopoly in somewhat different ways. Many don’t know about the auction rule. Others replenish Free Parking with a new $500 bill after someone lands on it. Also, many people disregard altogether the property assessment card while sticklers like me assess penalties when that vaunted red card appears.
4. Personal relationships can largely determine the outcome in both. Negotiation is key on IT projects. Clients negotiate rates, prices, and responsibilities with consulting vendors and/or software vendors.
In Monopoly, personal rivalries play a big part in who makes a deal with whom. Often players chime in (uninvited, of course) with their opinions on potential deals, without a doubt to affect the outcome.
5. Little things really matter, especially at the end. Towards the end of an IT project, snakes in the woodwork often come out to bite people when they least expect it. A tightly staffed or planned project may not be able to withstand a relatively minor problem, especially if the go-live date is non-negotiable.
In Monopoly, the same holds true. Laugh all you want when your opponent builds hotels on Mediterranean Avenue and Baltic Avenue, but at the end of the game those $250 and $450 charges can really hurt, especially when you’re low on cash.
6. Many times, each does not end; it is merely abandoned. A good percentage of projects have their plugs pulled prior to completion. A CIO may become tired with an interminable project and decide to simply end it before costs skyrocket even further.
I’d say that about half of the Monopoly games that I’ve played in the last fifteen years have also been called by “executive decision.” The writing is on the board, as 1 a.m. rolls around and only two players remain. Often player X simply cedes the game to player Y.
You are the Referee
All bouts require a referee. Blog-bouts are refereed by the readers. Therefore, please cast your vote in the poll and also weigh in on this debate by sharing your thoughts by posting a comment below. Since a blog-bout is co-posted, your comments will be copied (with full attribution) into the comments section of both of the blogs co-hosting this blog-bout.
About Jim Harris
Jim Harris is the Blogger-in-Chief at Obsessive-Compulsive Data Quality (OCDQ), which is an independent blog offering a vendor-neutral perspective on data quality. Jim is also an independent consultant, speaker, writer and blogger with over 15 years of professional services and application development experience in data quality (DQ), data integration, data warehousing (DW), business intelligence (BI), customer data integration (CDI), and master data management (MDM). Jim is also a contributing writer to Data Quality Pro, the leading online magazine and community resource dedicated to data quality professionals.
“Competency is a state of mind you reach when you’ve made enough mistakes.”
One of my continuing challenges is staying informed about the latest trends in data quality and its related disciplines, including Master Data Management (MDM), Dystopian Automated Transactional Analysis (DATA), and Data Governance (DG) – I am fairly certain that one of those three things isn't real, but I haven't figured out which one yet.
I read all of the latest books, as well as the books that I was supposed to have read years ago, when I was just pretending to have read all of the latest books. I also read the latest articles, whitepapers, and blogs. And I go to as many conferences as possible.
The basis of this endless quest for knowledge is fear. Please understand – I have never been afraid to look like an idiot. After all, we idiots are important members of society – we make everyone else look smart by comparison.
However, I also market myself as a data quality expert. Therefore, when I consult, speak, write, or blog, I am always at least a little afraid of not getting things quite right. Being afraid of making mistakes can drive you crazy.
But as a wise man named Seal Henry Olusegun Olumide Adeola Samuel (wisely better known by only his first name) lyrically taught us back in 1991:
“We're never gonna survive unless, we get a little crazy.”
“It’s not about getting things right in your brain,” explains D’Souza, “it’s about getting things wrong. The brain has to make hundreds, even thousands of mistakes — and overcome those mistakes — to be able to reach a level of competency.”
So, get a little crazy, make a lot of mistakes, and never stop learning.
“A storm is brewing—a perfect storm of viral data, disinformation, and misinformation.”
These cautionary words (written by Timothy G. Davis, an Executive Director within the IBM Software Group) are from the foreword of the remarkable new book Viral Data in SOA: An Enterprise Pandemic by Neal A. Fishman.
“Viral data,” explains Fishman, “is a metaphor used to indicate that business-oriented data can exhibit qualities of a specific type of human pathogen: the virus. Like a virus, data by itself is inert. Data requires software (or people) for the data to appear alive (or actionable) and cause a positive, neutral, or negative effect.”
“Viral data is a perfect storm,” because as Fishman explains, it is “a perfect opportunity to miscommunicate with ubiquity and simultaneity—a service-oriented pandemic reaching all corners of the enterprise.”
“The antonym of viral data is trusted information.”
Data Quality
“Quality is a subjective term,” explains Fishman, “for which each person has his or her own definition.” Fishman goes on to quote from many of the published definitions of data quality, including a few of my personal favorites:
David Loshin: “Fitness for use—the level of data quality determined by data consumers in terms of meeting or beating expectations.”
Danette McGilvray: “The degree to which information and data can be a trusted source for any and/or all required uses. It is having the right set of correct information, at the right time, in the right place, for the right people to use to make decisions, to run the business, to serve customers, and to achieve company goals.”
Thomas Redman: “Data are of high quality if those who use them say so. Usually, high-quality data must be both free of defects and possess features that customers desire.”
Data quality standards provide a highest common denominator to be used by all business units throughout the enterprise as an objective data foundation for their operational, tactical, and strategic initiatives. Starting from this foundation, information quality standards are customized to meet the subjective needs of each business unit and initiative. This approach leverages a consistent enterprise understanding of data while also providing the information necessary for day-to-day operations.
However, the enterprise-wide data quality standards must be understood as dynamic. Therefore, enforcing strict conformance to data quality standards can be self-defeating. On this point, Fishman quotes Joseph Juran: “conformance by its nature relates to static standards and specification, whereas quality is a moving target.”
Defining data quality is both an essential and challenging exercise for every enterprise. “While a succinct and holistic single-sentence definition of data quality may be difficult to craft,” explains Fishman, “an axiom that appears to be generally forgotten when establishing a definition is that in business, data is about things that transpire during the course of conducting business. Business data is data about the business, and any data about the business is metadata. First and foremost, the definition as to the quality of data must reflect the real-world object, concept, or event to which the data is supposed to be directly associated.”
Data Governance
“Data governance can be used as an overloaded term,” explains Fishman, and he quotes Jill Dyché and Evan Levy to explain that “many people confuse data quality, data governance, and master data management.”
“The function of data governance,” explains Fishman, “should be distinct and distinguishable from normal work activities.”
For example, although knowledge workers and subject matter experts are necessary to define the business rules for preventing viral data, according to Fishman, these are data quality tasks and not acts of data governance.
However, these data quality tasks must “subsequently be governed to make sure that all the requisite outcomes comply with the appropriate controls.”
Therefore, according to Fishman, “data governance is a function that can act as an oversight mechanism and can be used to enforce controls over data quality and master data management, but also over data privacy, data security, identity management, risk management, or be accepted in the interpretation and adoption of regulatory requirements.”
Conclusion
“There is a line between trustworthy information and viral data,” explains Fishman, “and that line is very fine.”
Poor data quality is a viral contaminant that will undermine the operational, tactical, and strategic initiatives essential to the enterprise's mission to survive and thrive in today's highly competitive and rapidly evolving marketplace.
Left untreated or unchecked, this infectious agent will negatively impact the quality of business decisions. As the pathogen replicates, more and more decision-critical enterprise information will be compromised.
According to Fishman, enterprise data quality requires a multidisciplinary effort and a lifetime commitment to:
“Prevent viral data and preserve trusted information.”
“I am putting myself to the fullest possible use, which is all I think that any conscious entity can ever hope to do.”
As I get closer and closer to my 2001st tweet on Twitter, I wanted to pause for some quiet reflection on my personal odyssey in social media – but then I decided to blog about it instead.
The Dawn of OCDQ
Except for LinkedIn, my epic drama of social media adventure and exploration started with my OCDQ blog.
In my Data Quality Pro article Blogging about Data Quality, I explained why I started this blog and discussed some of my thoughts on blogging. Most importantly, I explained that I am neither a blogging expert nor a social media expert.
But now that I have been blogging and using social media for over six months, I feel more comfortable sharing my thoughts and personal experiences with social media without worrying about sounding like too much of an idiot (no promises, of course).
LinkedIn
My social media odyssey began in 2007 when I created my account on LinkedIn, which I admit, I initially viewed as just an online resume. I put little effort into my profile, only made a few connections, and only joined a few groups.
Last year (motivated by the economic recession), I started using LinkedIn more extensively. I updated my profile with a complete job history, asked my colleagues for recommendations, expanded my network with more connections, and joined more groups. I also used LinkedIn applications (e.g. Reading List by Amazon and Blog Link) to further enhance my profile.
My favorite feature is the LinkedIn Groups, which not only provide an excellent opportunity to connect with other users, but also provide Discussions, News (including support for RSS feeds), and Job Postings.
By no means a comprehensive list, here are some LinkedIn Groups that you may be interested in:
Shortly after launching my blog in March 2009, I created my Twitter account to help promote my blog content. In blogging, content is king, but marketing is queen. LinkedIn (via group news feeds) is my leading source of blog visitors from social media, but Twitter isn't far behind.
However, as Michele Goetz of Brain Vibe explained in her blog post Is Twitter an Effective Direct Marketing Tool?, Twitter has a click-through rate equivalent to direct mail. Citing research from Pear Analytics, a “useful” tweet was found to have a shelf life of about one hour with about a 1% click-through rate on links.
In his blog post Is Twitter Killing Blogging?, Ajay Ohri of Decision Stats examined whether Twitter was a complement or a substitute for blogging. I created a Data Quality on Twitter page on my blog in order to illustrate what I have found to be the complementary nature of tweeting and blogging.
Most of my social networking is done using Twitter (with LinkedIn being a close second). I have also found Twitter to be great for doing research, which I complement with RSS subscriptions to blogs.
I also created my Facebook account shortly after launching my blog. Although I almost exclusively use social media for professional purposes, I do use Facebook as a way to stay connected with family and friends.
I created a page for my blog to separate my professional and personal aspects of Facebook without the need to manage multiple accounts. Additionally, this allows you to become a “fan” of my blog without requiring you to also become my “friend.”
A quick note on Facebook games, polls, and trivia: I do not play them. With my obsessive-compulsive personality, I have to ignore them. Therefore, please don't be offended if for example, I have ignored your invitation to play Mafia Wars.
By no means a comprehensive list, here are some Facebook Pages or Groups that you may be interested in:
Although LinkedIn, Twitter, and Facebook are my primary social media websites, I also have accounts on three of the most popular social bookmarking websites: Digg, StumbleUpon, and Delicious.
Social bookmarking can be a great promotional tool that can help blog content go viral. However, niche content is almost impossible to get to go viral. Data quality is not just a niche – if technology blogging was a Matryoshka (a.k.a. Russian nested) doll, then data quality would be the last, innermost doll.
This doesn't mean that data quality isn't an important subject – it just means that you will not see a blog post about data quality hitting the front pages of mainstream social bookmarking websites anytime soon. Dylan Jones of Data Quality Pro created DQVote, which is a social bookmarking website dedicated to sharing data quality community content.
I also have an account on FriendFeed, which is an aggregator that can consolidate content from other social media websites, blogs or anything providing a RSS feed. My blog posts and my updates from other social media websites (except for Facebook) are automatically aggregated. On Facebook, my personal page displays my FriendFeed content.
Social Media Tools and Services
Social media tools and services that I personally use (listed in no particular order):
“A home base,” explains Rowse, “is a place online that you own.” For example, your home base could be your blog or your company's website. “Outposts,” continues Rowse, “are places that you have an online presence out in other parts of the web that you might not own.” For example, your outposts could be your LinkedIn, Twitter, and Facebook accounts.
According to Rowse, your Outposts will make your Home Base stronger by providing:
“Relationships, ideas, traffic, resources, partnerships, community and much more.”
Social Karma
An effective social media strategy is essential for both companies and individual professionals. Using social media can help promote you, your expertise, your company and your products and services.
However, too many companies and individuals have a selfish social media strategy.
You should not use social media exclusively for self-promotion. You should view social media as Social Karma.
If you can focus on helping others when you use social media, then you will get much more back than just a blog reader, a LinkedIn connection, a Twitter follower, a Facebook friend, or even a potential customer.
Yes, I use social media to promote myself and my blog content. However, more than anything else, I use social media to listen, to learn, and to help others when I can.
Please Share Your Social Media Odyssey
As always, I am interested in hearing from you. What have been your personal experiences with social media?
I define data using the Dragnet definition – it is “just the facts” collected as an abstract description of the real-world entities that the enterprise does business with (e.g. customers, vendors, suppliers). A common definition for data quality is fitness for the purpose of use, the common challenge is that data has multiple uses – each with its own fitness requirements. Viewing each intended use as the information that is derived from data, I define informationas data in use or data in action.
Alternatively, information can be defined as data in context.
Quality, as Sherman explains, “is in the eyes of the beholder, i.e. the business context.”
In Part 5 of this series: You completed your initial analysis of the fields relating to postal address with the investigation of Postal Address Line 1 and Postal Address Line 2.
You saw additional examples of why free-form fields are often easier to analyze as formats constructed by parsing and classifying the individual values within the field.
You learned this analysis technique is often necessary since not only is the cardinality of free-form fields usually very high, but they also tend to have a very high Distinctness (i.e. the exact same field value rarely occurs on more than one record).
You also saw examples of how the most frequently occurring formats for free-form fields will often collectively account for a large percentage of the records with an actual value in the field.
In Part 6, you will continue your adventures in data profiling by analyzing the Account Number and Tax ID fields.
Account Number
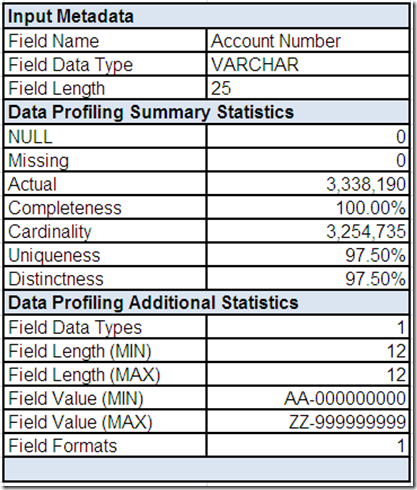
The field summary for Account Number includes input metadata along with the summary and additional statistics provided by the data profiling tool.
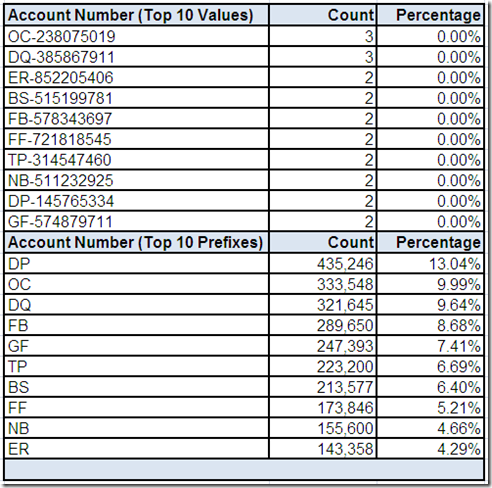
In Part 2, we learned that Customer ID is likely an integer surrogate key and the primary key for this data source because it is both 100% complete and 100% unique. Account Number is 100% complete and almost 100% unique. Perhaps it was intended to be the natural key for this data source?
Let's assume that drill-downs revealed the single profiled field data type was VARCHAR and the single profiled field format was aa-nnnnnnnnn (i.e. 2 characters, followed by a hyphen, followed by a 9 digit number).
Combined with the profiled minimum/maximum field lengths, the good news appears to be that not only is Account Number always populated, it is also consistently formatted.
The profiled minimum/maximum field values appear somewhat suspicious, possibly indicating the presence of invalid values?
We can use drill-downs on the field summary “screen” to get more details about Account Number provided by the data profiling tool.
The cardinality of Account Number is very high, as is its Distinctness (i.e. the same field value rarely occurs on more than one record). Therefore, when we limit the review to only the top ten most frequently occurring values, it is not surprising to see low counts.
Since we do not yet have a business understanding of the data, we are not sure if it is valid for multiple records to have the same Account Number.
Additional analysis can be performed by extracting the alpha prefix and reviewing its top ten most frequently occurring values. One aspect of this analysis is that it can be used to assess the possibility that Account Number is an “intelligent key.” Perhaps the alpha prefix is a source system code?
Tax ID
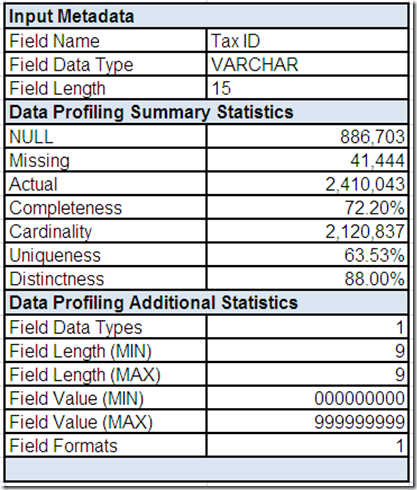
The field summary for Tax ID includes input metadata along with the summary and additional statistics provided by the data profiling tool.
Let's assume that drill-downs revealed the single profiled field data type was INTEGER and the single profiled field format was nnnnnnnnn (i.e. a 9 digit number).
Combined with the profiled minimum/maximum field lengths, the good news appears to be that Tax ID is also consistently formatted. However, the profiled minimum/maximum field values appear to indicate the presence of invalid values.
In Part 4, we learned that most of the records appear to have either an United States (US) or Canada (CA) postal address. For US records, the Tax ID field could represent the social security number (SSN), federal employer identification number (FEIN), or tax identification number (TIN). For CA records, this field could represent the social insurance number (SIN). All of these identifiers are used for tax reporting purposes and have a 9 digit number format (when no presentation formatting is used).
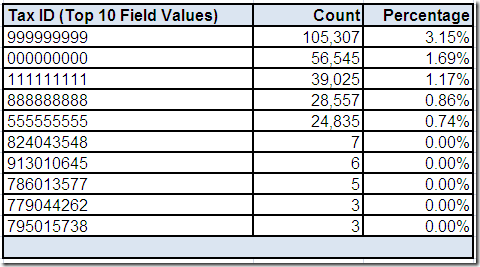
We can use drill-downs on the field summary “screen” to get more details about Tax ID provided by the data profiling tool.
The Distinctness of Tax ID is slightly lower than Account Number and therefore the same field value does occasionally occur on more than one record.
Since the cardinality of Tax ID is very high, we will limit the review to only the top ten most frequently occurring values. This analysis reveals the presence of more (most likely) invalid values.
Potential Duplicate Records
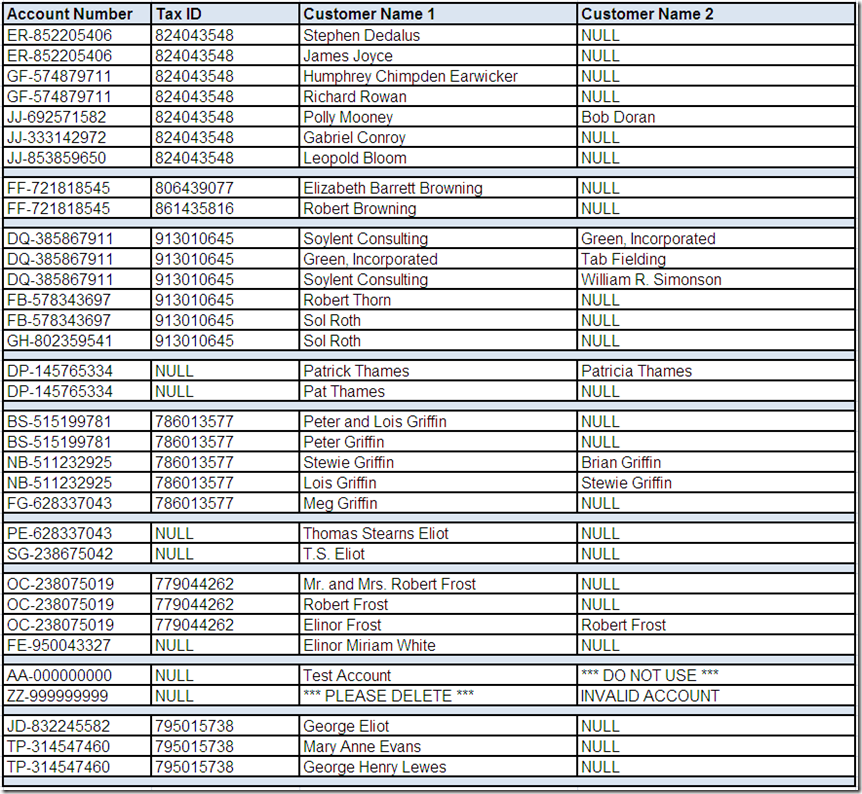
In Part 1, we asked if the data profiling statistics for Account Number and/or Tax ID indicate the presence of potential duplicate records. In other words, since some distinct actual values for these fields occur on more than one record, does this imply more than just a possible data relationship, but a possible data redundancy? Obviously, we would need to interact with the business team in order to better understand the data and their business rules for identifying duplicate records.
However, let's assume that we have performed drill-down analysis using the data profiling tool and have selected the following records of interest:
What other analysis do you think should be performed for these fields?
In Part 7 of this series: We will continue the adventures in data profiling by completing our initial analysis with the investigation of the Customer Name 1 and Customer Name 2 fields.
“It is a truth universally acknowledged, that a blogger in possession of a good domain must be in want of some worthwhile comments.”
“The most rewarding thing has been that comments,” explained Hanagarne, “led to me meeting some great people I possibly never would have known otherwise.” I wholeheartedly echo that sentiment.
This is the second entry in my ongoing series celebrating my heroes – my readers.
“This article is intriguing. I would add more still.
A most significant quote: 'Data could be considered a constant while Information is a variable that redefines data for each specific use.'
This tells us that Information draws from a snapshot of a Data store. I would state further that the very Information [specification] is – in itself – a snapshot.
The earlier quote continues: 'Data is not truly a constant since it is constantly changing.'
Similarly, it is a business reality that 'Information is not truly a constant since it is constantly changing.'
The article points out that 'The Data-Information Continuum' implies a many-to-many relationship between the two. This is a sensible CONCEPTUAL model.
Enterprise Architecture is concerned as well with its responsibility for application quality in service to each Business Unit/Initiative.
For example, in the interest of quality design in Application Architecture, an additional LOGICAL model must be maintained between a then-current Information requirement and the particular Data (snapshots) from which it draws. [Snapshot: generally understood as captured and frozen – and uneditable – at a particular point in time.] Simply put, Information Snapshots have a PARENT RELATIONSHIP to the Data Snapshots from which they draw.
Analyzing this further, refer to this further piece of quoted wisdom (from section 'Subjective Information Quality'): '...business units and initiatives must begin defining their Information...by using...Data...as a foundation...necessary for the day-to-day operation of each business unit and initiative.'
From logically-related snapshots of Information to the Data from which it draws, we can see from this quote that yet another PARENT/CHILD relationship exists...that from Business Unit/Initiative Snapshots to the Information Snapshots that implement whatever goals are the order of the day. But days change.
If it is true that 'Data is not truly a constant since it is constantly changing,' and if we can agree that Information is not truly a constant either, then we can agree to take a rational and profitable leap to the truth that neither is a Business Unit/Initiative...since these undergo change as well, though they represent more slowly-changing dimensions.
Enterprises have an increasing responsibility for regulatory/compliance/archival systems that will qualitatively reproduce the ENTIRE snapshot of a particular operational transaction at any given point in time.
Thus, the Enterprise Architecture function has before it a daunting task: to devise a holistic process that can SEAMLESSLY model the correct relationship of snapshots between Data (grandchild), Information (parent) and Business Unit/Initiative (grandparent).
There need be no conversion programs or redundant, throw-away data structures contrived to bridge the present gap. The ability to capture the activities resulting from the undeniable point-in-time hierarchy among these entities is where tremendous opportunities lie.”
“My favorite quote is 'Instead of focusing on the exceptions – focus on the improvements.'
I think that it is really important to define incremental goals for data quality projects and track the progress through percentage improvement over a period of time.
I think it is also important to manage the expectations that the goal is not necessarily to reach 100% (which will be extremely difficult if not impossible) clean data but the goal is to make progress to a point where the purpose for cleaning the data can be achieved in much better way than had the original data been used.
For example, if marketing wanted to use the contact data to create a campaign for those contacts which have a certain ERP system installed on-site. But if the ERP information on the contact database is not clean (it is free text, in some cases it is absent etc...) then any campaign run on this data will reach only X% contacts at best (assuming only X% of contacts have ERP which is clean)...if the data quality project is undertaken to clean this data, one needs to look at progress in terms of % improvement. How many contacts now have their ERP field cleaned and legible compared to when we started etc...and a reasonable goal needs to be set based on how much marketing and IT is willing to invest in these issues (which in turn could be based on ROI of the campaign based on increased outreach).”
“My theory of the data, information, knowledge continuum is more closely related to the element, compound, protein, structure arc.
In my world, there is no such thing as 'bad' data, just as there is no 'bad' elements. Data is either useful or not: the larger the audience that agrees that a string is representative of something they can use, the more that string will be of value to me.
By dint of its existence in the world of human communication and in keeping with my theory, I can assign every piece of data to one of a fixed number of classes, each with characteristics of their own, just like elements in the periodic table. And, just like the periodic table, those characteristics do not change. The same 109 usable elements in the periodic table are found and are consistent throughout the universe, and our ability to understand that universe is based on that stability.
Information is simply data in a given context, like a molecule of carbon in flour. The carbon retains all of its characteristics but the combination with other elements allows it to partake in a whole class of organic behavior. This is similar to the word 'practical' occurring in a sentence: Jim is a practical person or the letter 'p' in the last two words.
Where the analogue bends a bit is a cause of a lot of information management pain, but can be rectified with a slight change in perspective. Computers (and almost all indexes) have a hard time with homographs: strings that are identical but that mean different things. By creating fixed and persistent categories of data, my model suffers no such pain.
Take the word 'flies' in the following: 'Time flies like an arrow.' and 'Fruit flies like a pear.' The data 'flies' can be permanently assigned to two different places, and their use determines which instance is relevant in the context of the sentence. One instance is a verb, the other a plural noun.
Knowledge, in my opinion, is the ability to recognize, predict and synthesize patterns of information for past, present and future use, and more importantly to effectively communicate those patterns in one or more contexts to one or more audiences.
On one level, the model for information management that I use makes no apparent distinction between the data: we all use nouns, adjectives, verbs and sometimes scalar objects to communicate. We may compress those into extremely compact concepts but they can all be unraveled to get at elemental components. At another level every distinction is made to insure precision.
The difference between information and knowledge is experiential and since experience is an accumulative construct, knowledge can be layered to appeal to common knowledge, special knowledge and unique knowledge.
Common being the most easily taught and widely applied; Special being related to one or more disciplines and/or special functions; and, Unique to individuals who have their own elevated understanding of the world and so have a need for compact and purpose-built semantic structures.
Going back to the analogue, knowledge is equivalent to the creation by certain proteins of cartilage, the use to which that cartilage is put throughout a body, and the specific shape of the cartilage that forms my nose as unique from the one on my wife's face.
To me, the most important part of the model is at the element level. If I can convince a group of people to use a fixed set of elemental categories and to reference those categories when they create information, it's amazing how much tension disappears in the design, creation and deployment of knowledge.”
Tá mé buíoch díot
Daragh O Brien recently taught me the Irish Gaelic phrase Tá mé buíoch díot, which translates as I am grateful to you.
I am very grateful to all of my readers. Since there have been so many commendable comments, please don't be offended if your commendable comment hasn't been featured yet. Please keep on commenting and stay tuned for future entries in the series.
In the book, Redman explains that this advice is a rewording of his favorite data quality policy of all time.
Assuming that it is someone else's responsibility is a fundamental root case for enterprise data quality problems. One of the primary goals of a data quality initiative must be to define the roles and responsibilities for data ownership and data quality.
In sports, it is common for inspirational phrases to be posted above every locker room exit door. Players acknowledge and internalize the inspirational phrase by reaching up and touching it as they head out onto the playing field.
Perhaps you should post this DQ-Tip above every break room exit door throughout your organization?
“What you don’t know is far more relevant than what you do know.”
Our tendency is to believe the opposite. After we have accumulated the information required to be considered knowledgeable in our field, we believe that what we have learned and experienced (i.e. what we know) is far more relevant than what we don’t know. We are all proud of our experience, which we believe is the path that separates knowledge from wisdom.
“We tend to treat our knowledge as personal property to be protected and defended,” explains Taleb. “It is an ornament that allows us to rise in the pecking order. We take what we know a little too seriously.”
However, our complacency is all too often upset by the unexpected. Some new evidence is discovered that disproves our working theory of how things work. Or something that we have repeatedly verified in the laboratory of our extensive experience, suddenly doesn’t produce the usual results.
Taleb cautions that this “illustrates a severe limitation to our learning from experience and the fragility of our knowledge.”
I have personally encountered this many times throughout my career in data quality. At first, it seemed like a cruel joke or some bizarre hazing ritual. Every time I thought that I had figured it all out, that I had learned all the rules, something I didn’t expect would come along and smack me upside the head.
“We do not spontaneously learn,” explains Taleb, “that we don’t learn that we don’t learn. The problem lies in the structure of our minds: we don’t learn rules, just facts, and only facts.”
Facts are important. Facts are useful. However, sometimes our facts are really only theories. Mistaking a theory for a fact can be very dangerous. What you don’t know can hurt you.
However, as Taleb explains, “what you know cannot really hurt you.” Therefore, we tend to only “look at what confirms our knowledge, not our ignorance.” This is unfortunate, because “there are so many things we can do if we focus on antiknowledge, or what we do not know.”
This is why, as a data quality consultant, when I begin an engagement with a new client, I usually open with the statement (completely without sarcasm):