Data and its Relationships with Quality
/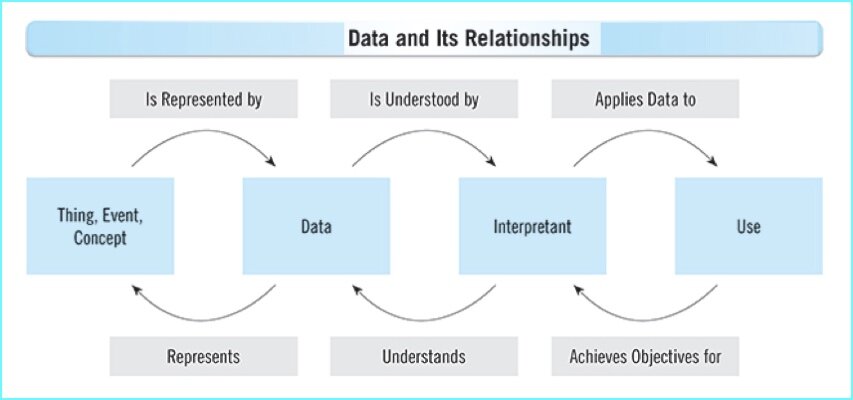
The title of this blog post is an allusion to the graphic (shown above) that accompanied an Information Management column by Malcolm Chisholm, in which he wrote that data quality is not fitness for use as it is most commonly defined, stating he thinks “a strong case can be made that the definition is indeed inappropriate and should be replaced with a better one.”
“Before we get into the definition of data quality, let us take a brief look at what data is related to,” Chisholm opened, explaining that “data represents something — a thing, event, or concept.”
As I blogged in my post Plato’s Data, whether it’s an abstract description of real-world entities (i.e., “master data”) or an abstract description of real-world interactions (i.e., “transaction data”) among entities, data is an abstract description of reality. Although data shapes our perception of the real world, sometimes we forget that data is only a partial reflection of reality.
“Data is understood,” Chisholm continued, “by something, for which the best term I can find is the interpretant.”
“The interpretant applies the data to one or more uses, which achieve objectives the interpretant has. The interpretant is independent of the data. It understands the data and can put it to use. But if the interpretant misunderstands the data, or puts it to an inappropriate use, that is hardly the fault of the data, and cannot constitute a data quality problem.”
As I blogged in my post Quality is the Higgs Field of Data, independent from use, data is as carefree as the mass-less photon whizzing around at the speed of light. But once we interact with it, data begins to feel the effects of our use. We give data mass so that it can become the basic building blocks of what matters to us. Some data is affected more by our use than others. The more subjective our use, the more we weigh data down. The more objective our use, the less we weigh data down.
“A more fundamental problem is that data can have many uses,” Chisholm continued. “If we think data quality is fitness for use, then data quality must be assessed independently for each use we put it to.” Instead, Chisholm contends that data quality is “an expression of the relationship between the thing, event, or concept and the data that represents it. This is a one-to-one relationship, unlike the one-to-many relationship between data and uses.”
Therefore, Chisholm proposes that a better definition of data quality is “the extent to which the data actually represents what it purports to represent. This definition can be used to think of data quality as a property of the data itself, and then our diagnosis and remediation efforts will focus on the special problems of the relationship between data and what it represents.”
But, of course, although Chisholm doesn’t like it as a definition for data quality, he is not denying that fitness for use describes “a set of valid concepts that deal with types of problems around the use of data.” Two examples he cites are when the interpretant misunderstands the data, or when the interpretant uses data for a purpose that is incompatible with the data.
In his conclusion, Chisholm states that “the special problems of the relationships between data and what it is used for requires a different set of approaches and should be called something other than data quality.”
And this is exactly why, as I blogged in my post Data Myopia and Business Relativity, many data professionals prefer to define data quality as real-world alignment and information quality as fitness for the purpose of use. However, I have found that adding the nuance of data versus information only further complicates data quality discussions with business professionals.
Chisholm also suggests that his proposed definition of data quality is not only better, but that “it also alludes to the existence of metadata that links the data to what it is representing.” The important role that metadata plays in supporting data and its relationships with information and quality is something I blogged about in my post You Say Potato and I Say Tater Tot.
The irony is the metadata that links the data management industry to what it is representing that it manages suffers from the one-to-many relationships we’ve created by seemingly never agreeing on how data, information, and quality should be defined.
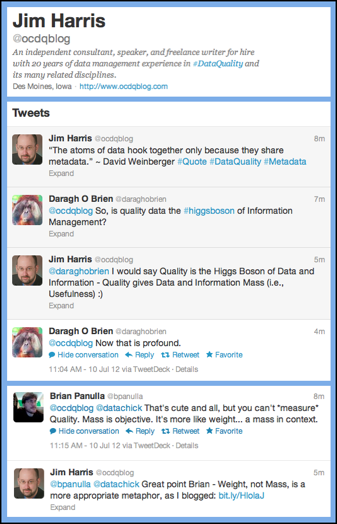 Recently on Twitter,
Recently on Twitter, 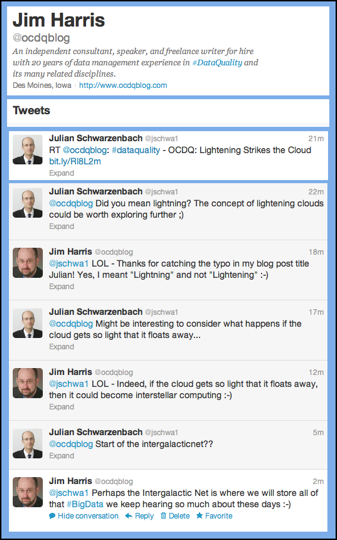 Last week, when I published my blog post
Last week, when I published my blog post