Commendable Comments (Part 6)
/Last September, and on the exact day of the sixth mensiversary (yes, that’s a real word, look it up) of my blog, I started this series as an ongoing celebration of the truly commendable comments that I regularly receive from my heroes—my readers.
Commendable Comments
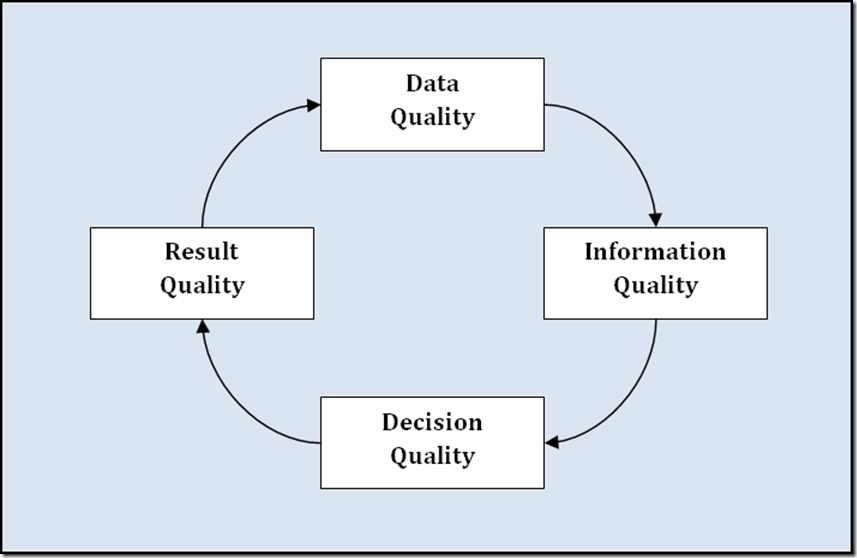
On The Circle of Quality, Kelly Lautt commented:
“One of the offerings I provide as a consultant is around data readiness specifically for BI. Sometimes, you have to sneak an initial data quality project into a company tightly connected to a project or initiative with a clear, already accepted (and budgeted) ROI. Once the client sees the value of data quality vis a vis the BI requirements, it is easier to then discuss overall data quality (from multiple perspectives).
And, I have to add, I do feel that massive, cumbersome enterprise DQ programs sometimes lose the plot by blindly ‘improving’ data without any value in sight. I think there has to be a balance between ignoring generalized DQ versus going overboard when there will be a diminishing return at some point.
Always drive effort and investment in any area (including DQ) from expected business value!”
On The Poor Data Quality Jar, Daragh O Brien commented:
“We actually tried to implement something like this with regard to billing data quality issues that created compliance problems. Our aim was to have the cost of fixing the problem borne by the business area which created the issue, with the ‘swear jar’ being the budget pool for remediation projects.
We ran into a few practical problems:
1) Many problems ultimately had multiple areas with responsibility (line-of-business workers bypassing processes, IT historically ‘right-sizing’ scope on projects, business processes and business requirements not necessarily being defined properly resulting in inevitable errors)
2) Politics often prevented us from pushing the evidence we did have too hard as to the weighting of contributions towards any issue.
3) More often than not it was not possible to get hard metrics on which to base a weighting of contribution, and people tended to object to being blamed for a problem that was obviously complex with multiple inputs.
That said, the attempt to do it did help us to:
1) Justify our ‘claims’ that these issues were often complex with multiple stakeholders involved.
2) Get stakeholders to think about the processes end-to-end, including the multiple IT systems that were involved in even the simplest process.
3) Ensure we had human resources assigned to projects because we had metrics to apply to a business case.
4) Start building a focus on prevention of defect rather than just error detection and fix.
We never got around to using electric shocks on anyone. But I’d be lying if I said it wasn’t a temptation.”
On The Poor Data Quality Jar, Julian Schwarzenbach commented:
“As data accuracy issues in some cases will be identified by front line staff, how likely are they going to be to report them? Whilst the electric chair would be a tempting solution for certain data quality transgressions, would it mean that more data quality problems are reported?
This presents a similar issue to that in large companies when they look at their accident reporting statistics and reports of near misses/near hits:
* Does a high number of reported accidents and near hits mean that the company is unsafe, or does it mean that there are high levels of reporting coupled with a supportive, learning culture?
* Does a low number of reported accidents and near hits mean that the company is safe, or does it mean that staff are too scared of repercussions to report anything?
If staff risk a large fine/electric shock for owning up to transgressions, they will not do it and will work hard to hide the evidence, if they can.
In organizational/industrial situations, there are often multiple contributing factors to accidents and data quality problems. To minimize the level of future problems, all contributory causes need to be identified and resolved. To achieve this, staff should not be victimized/blamed in any way and should be encouraged to report issues without fear.”
On The Scarlet DQ, Henrik Liliendahl Sørensen commented:
“When I think about the root causes of many of the data quality issues I have witnessed, the original data entry was actually made in good faith by people trying to make data fit for the immediate purpose of use. Honest, loyal, and hardworking employees striving to get the work done.
Who are the bad guys then? Either it is no one or everyone or probably both.
When I have witnessed data quality problems solved it is most often done by a superhero taking the lead in finding solutions. That superhero has been different kinds of people. Sometimes it is a CEO, sometimes a CFO, sometimes a CRM-manager, sometimes it is anyone else.”
On The Scarlet DQ, Jacqueline Roberts commented:
“I work with engineering data and I find that the users of the data are not the creators of data, so by the time that data quality is questioned the engineering project has been completed, the engineering teams have been disbanded and moved on to other projects for other facilities.
I am sure that if the engineers had to put the spare part components on purchasing contracts for plant maintenance, the engineers would start to understand some of the data quality issues such as incomplete part numbers or descriptions, missing information, etc.”
On The Scarlet DQ, Thorsten Radde commented:
“Is the question of ‘who is to blame’ really that important?
For me, it is more important to ask ‘what needs to be done to improve the situation.’
I don’t think that assigning blame helps much in improving the situation. It is very rare that people cooperate to ‘cover up their mistakes.’ I found it more helpful to point out why the current situation is ‘wrong’ and then brainstorm with people on what can be done about it - which additional conventions are required, what can be checked automatically, if new functionality is needed, etc.
Of course, to be able to do that, you’ve got to have the right people on board that trust each other - and the blame game doesn’t help at all. Maybe you need a ‘blame doll’ that everyone can beat in order to vent their frustrations and then move on to more constructive behavior?”
On Can Enterprise-Class Solutions Ever Deliver ROI?, James Standen commented:
“Fantastic question. I think the short answer of course as always is ‘it depends’.
However, what’s important is exactly WHAT does it depend on. And I think while the vendors of these solutions would like you to believe that it depends on the features and functionality of their various applications, that what it all depends on far more is the way they are installed, and to what degree the business actually uses them.
(Insert buzz words here like: ‘business process alignment’, ‘project ownership’, ‘Business/IT collaboration’)
But if you spend Gazillions on a new ERP, then customize it like crazy to ensure that none of your business processes have to change and none of your siloed departments have to talk to each other (which will cost another gazillion in development and consulting by the way), which will then ensure that ongoing maintenance and configuration is more expensive as well, and will eliminate any ability to use pre-built business intelligence solutions etc., etc. Your ROI is going to be a big, negative number.
Unfortunately, this is often how it’s done. So my first comment in this debate is - If enterprise systems enable real change and optimization in business processes, then they CAN have ROI. But it’s hard. And doesn't happen often enough.”
On Microwavable Data Quality, Dylan Jones commented:
“Totally agree with you that data cleansing has been by far the most polarizing topic featured on our site since the launch. Like you, I agree that data governance is a marathon not a sprint but I do object to a lot of the data cleansing bashing that goes on.
I think that sometimes we should give people who purchase cleansing software far more credit than many of the detractors would be willing to offer. In the vast majority of cases data cleansing does provide a positive ROI and whilst some could argue it creates a cost base within the organization it is still a step in the direction of data quality maturity.
I think this particular debate is going to run and run however so thanks for fanning the flames.”
On The Challenging Gift of Social Media, Crysta Anderson commented:
“This is the biggest mindshift for a lot of people. When we started Social Media, many wanted to build our program based only on the second circle - existing customers. We had to fight hard to prove that the third circle not only existed (we had a hunch it did), but that it was worth our time to pursue. Sure, we can't point to a direct sales ROI, but the value of building a ‘tribe’ that raises the conversation about data quality, MDM, data governance and other topics has been incredible and continues to grow.”
Thank You
Thank you all for your comments. Your feedback is greatly appreciated—and truly is the best part of my blogging experience.
Since there have been so many commendable comments, please don’t be offended if one of your comments wasn’t featured.
Please keep on commenting and stay tuned for future entries in the series.
Related Posts
Follow OCDQ
For more blog posts and commendable comments, subscribe to OCDQ via my RSS feed, my E-mail updates, or Google Reader.
You can also follow OCDQ on Twitter, fan the Facebook page for OCDQ, and connect with me on LinkedIn.